Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks
Authors: Weilin Xu, David Evans, Yanjun Qi
For class EE/CSC 7700 ML for CPS
Instructor: Dr. Xugui Zhou
Presentation by Group 5: Fozia Rajbdad
Time of Presentation:10:30 AM, Friday, September 27, 2024
Blog post by Group 9: Trevor Spinosa, Kendall Comeaux
Link to Paper:
https://arxiv.org/pdf/1704.01155
Slide Outlines
Summary of the Paper
The authors provide an overview of a technique called feature squeezing, which is used to detect adversarial examples in neural networks. Adversarials are subtle and can cause neural networks to malfunction and misclassify. Feature squeezing involves compressing the input feature space, making it more difficult for these adversarials to go unnoticed while also trying to preserve the original accuracy of the model. It involves transformations like bit depth reduction and spatial smoothing. The paper also explored attack methods including FGSM, BIM, and DeepFool, and evaluated the feature squeezing technique across different types of datasets. While the technique does have some limitations when given complex datasets, it remains a viable defense strategy against adversarial attacks.
Content

A brief overview of the presentation’s structure, highlighting the key areas: objectives, introduction, motivation, feature squeezers, detection methods, evaluation, limitations, summary, and discussion. This slide serves as a roadmap for understanding the rest of the presentation.
Objective

The main objective of this research is to detect adversarial examples in DNNs using a method known as feature squeezing. This approach compresses the feature space, making it harder for adversarial perturbations to evade detection, while maintaining the network's overall performance on clean data.
Introduction

This slide introduces the problem of adversarial examples—inputs that have been deliberately altered to cause deep learning models to misclassify. Adversarial attacks pose a significant threat to the security of machine learning systems, as the changes made to inputs can be nearly imperceptible to humans but catastrophic for models. The growing importance of detecting these attacks is emphasized in high-stakes applications like autonomous driving and cybersecurity.
Adversarial Sample
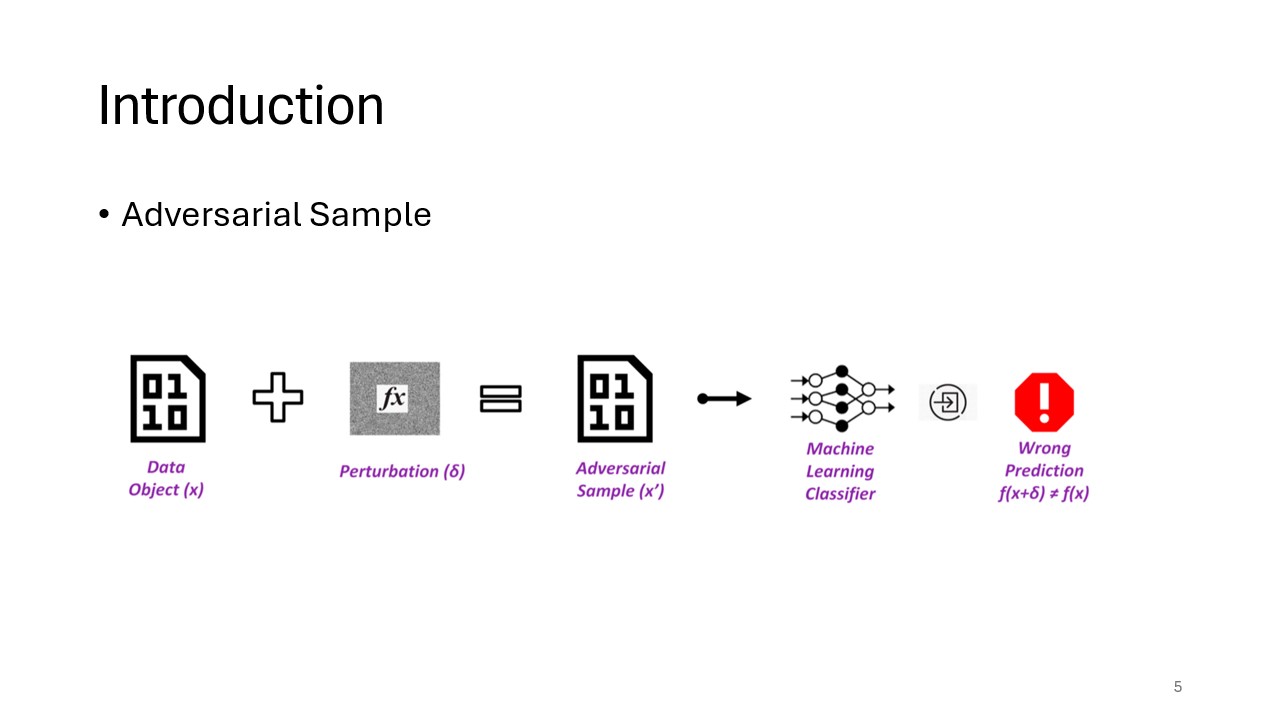
An adversarial example is an input designed to deceive a classifier into making incorrect predictions. This slide highlights how small, often imperceptible, alterations to input data can mislead even highly accurate classifiers. Understanding this concept is key to recognizing the vulnerability of neural networks to such attacks.
Types of Adversarial Examples

This slide explains the two primary categories of adversarial examples: targeted, where the attacker forces the model to classify an input as a specific wrong class, and untargeted, where any incorrect classification is the goal. The distinction helps inform different defense strategies.
Metrics for Adversarial Detection

Introduces the distance metrics used to detect adversarial examples. The LP-norm metrics measure the extent of changes between the original and adversarial examples, offering a way to quantify the perturbations. These metrics help in assessing the strength of adversarial attacks and the model's robustness.
Adversarial Attack Methods

This slide outlines common methods for generating adversarial examples, such as FGSM, BIM, DeepFool, and CW attacks. These methods represent various ways attackers can craft inputs to exploit vulnerabilities in neural networks.
Motivations

The motivations behind feature squeezing as a defense mechanism are outlined here. Traditional adversarial defenses, like adversarial training, can be computationally expensive. Feature squeezing provides a more efficient alternative by reducing the adversary's available search space, combining multiple feature vectors into one sample, and helping detect adversarial examples with minimal overhead.
Feature Squeezers
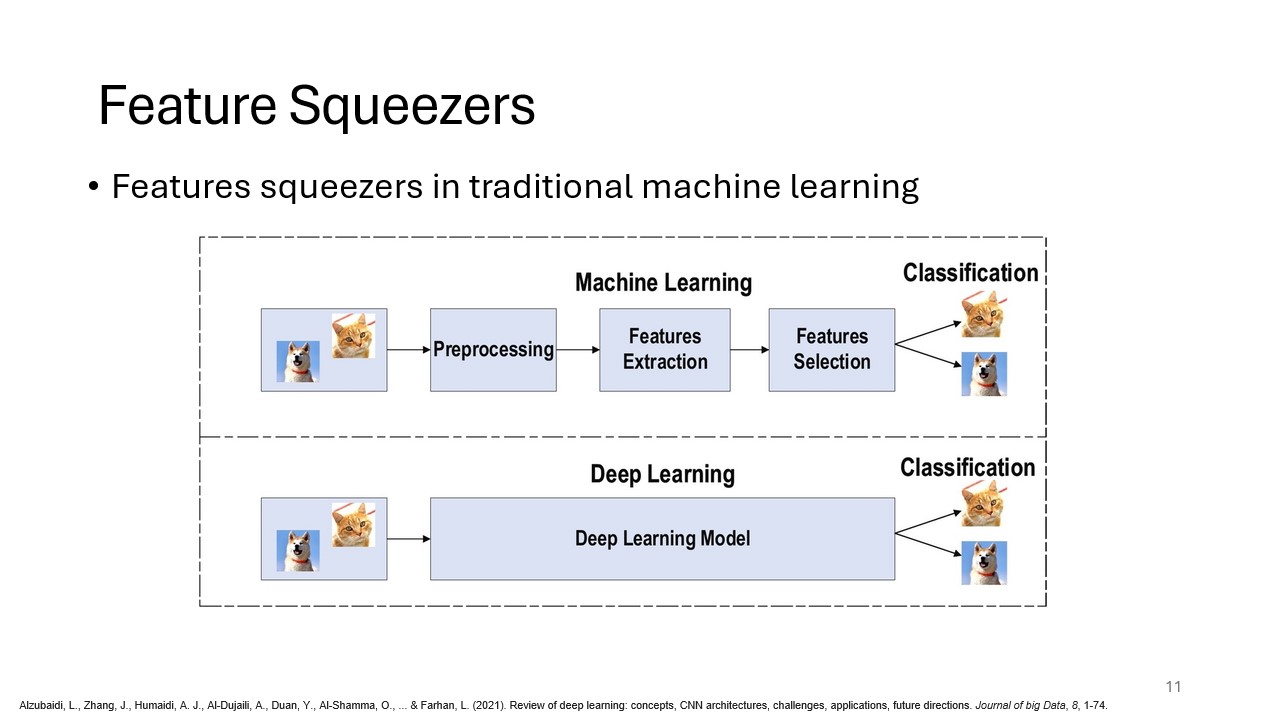
This slide introduces the core technique of feature squeezers, which apply transformations to reduce the complexity of input features. By combining similar feature vectors, feature squeezing can limit the space adversaries can exploit to craft attacks. This method enhances the ability to detect adversarial examples.
Detection Framework

The feature squeezing detection framework includes techniques such as bit depth reduction and spatial smoothing. These transformations make adversarial perturbations more noticeable by limiting the pixel-level variations an attacker can introduce while maintaining input semantics.
Block Diagram
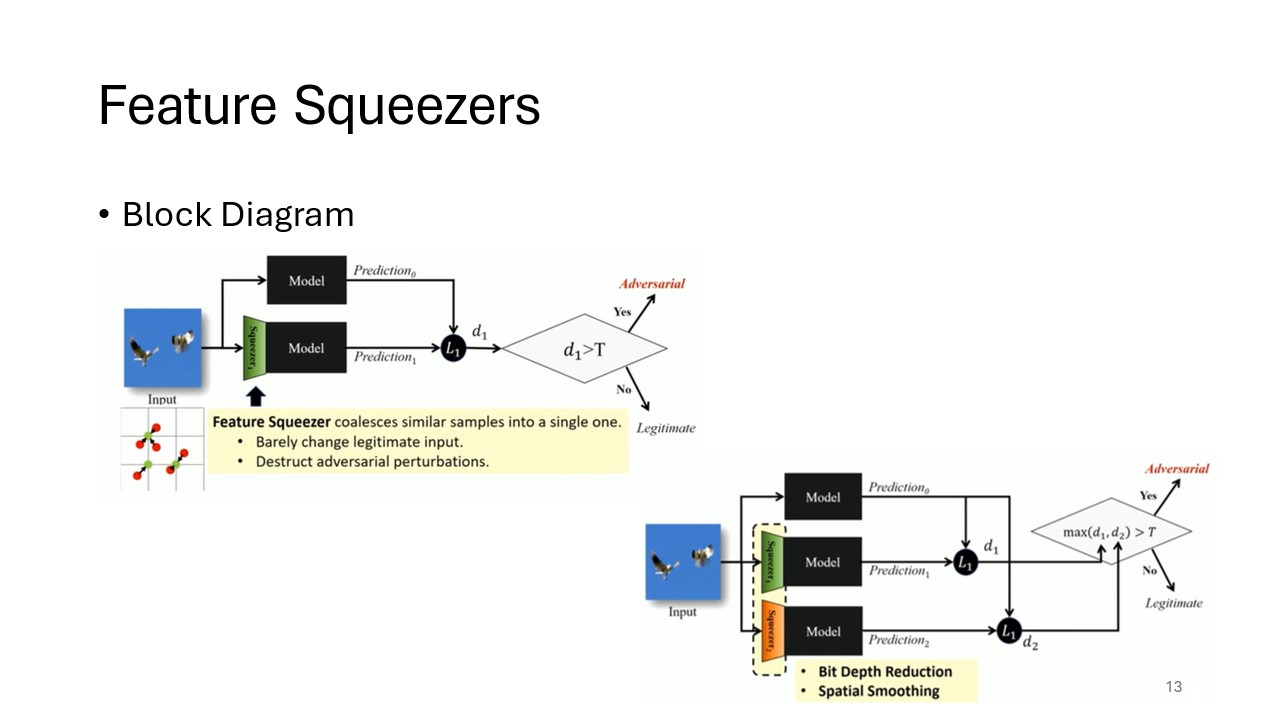
This diagram visually represents the feature squeezing detection framework. It provides an overview of how different feature squeezing techniques are applied to detect adversarial examples.
Bit Depth Reduction
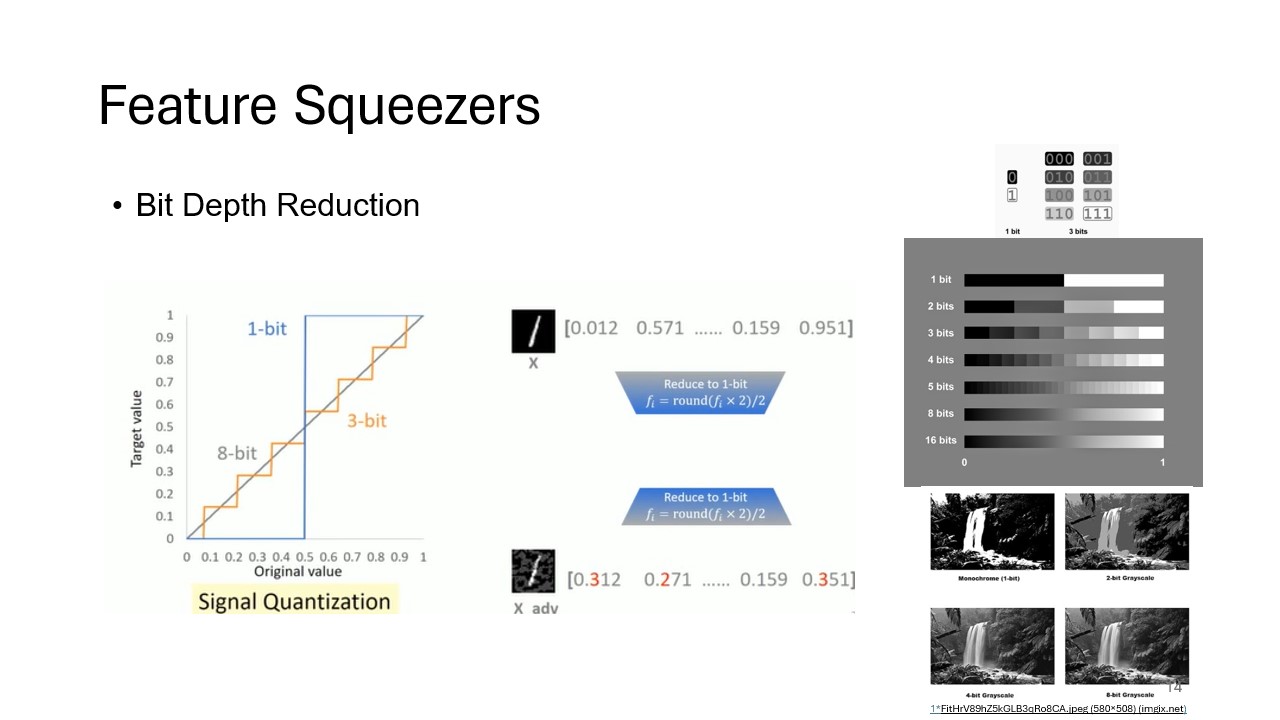
A core feature squeezing technique, bit depth reduction works by eliminating fine-grained adversarial perturbations while preserving the overall semantic content of the input. This slide shows how reducing bit depth limits the ability of attackers to subtly manipulate images.
Accuracy of Bit Depth Reduction

This slide discusses the effectiveness of bit depth reduction in detecting adversarial attacks while maintaining high accuracy for legitimate inputs. It highlights how feature squeezing can enhance model robustness.
Spatial Smoothing
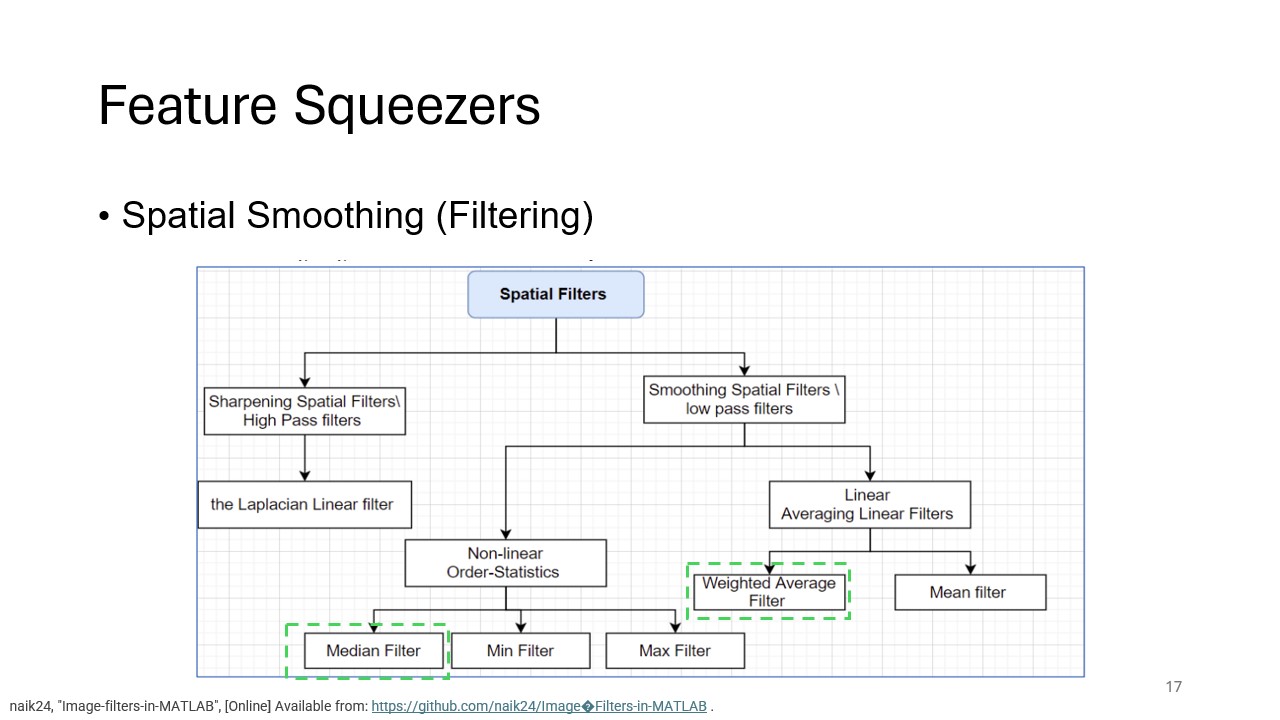
Spatial smoothing, another key feature squeezing method, is introduced here. This technique uses filtering (such as median filtering) to reduce noise and smooth out adversarial perturbations, particularly useful in mitigating attacks like salt-and-pepper noise.
Median Filtering

This slide provides an explanation of median filtering, a common spatial smoothing technique. By replacing a pixel’s value with the median of its neighboring pixels, this filter helps eliminate noise introduced by adversarial attacks, enhancing image integrity.
Non-Local Means Smoothing

This slide introduces non-local means smoothing, a more advanced spatial smoothing technique. Instead of just considering neighboring pixels, it averages pixels based on overall similarity, offering a more refined approach to mitigating adversarial noise.
Accuracy of Spatial Smoothing
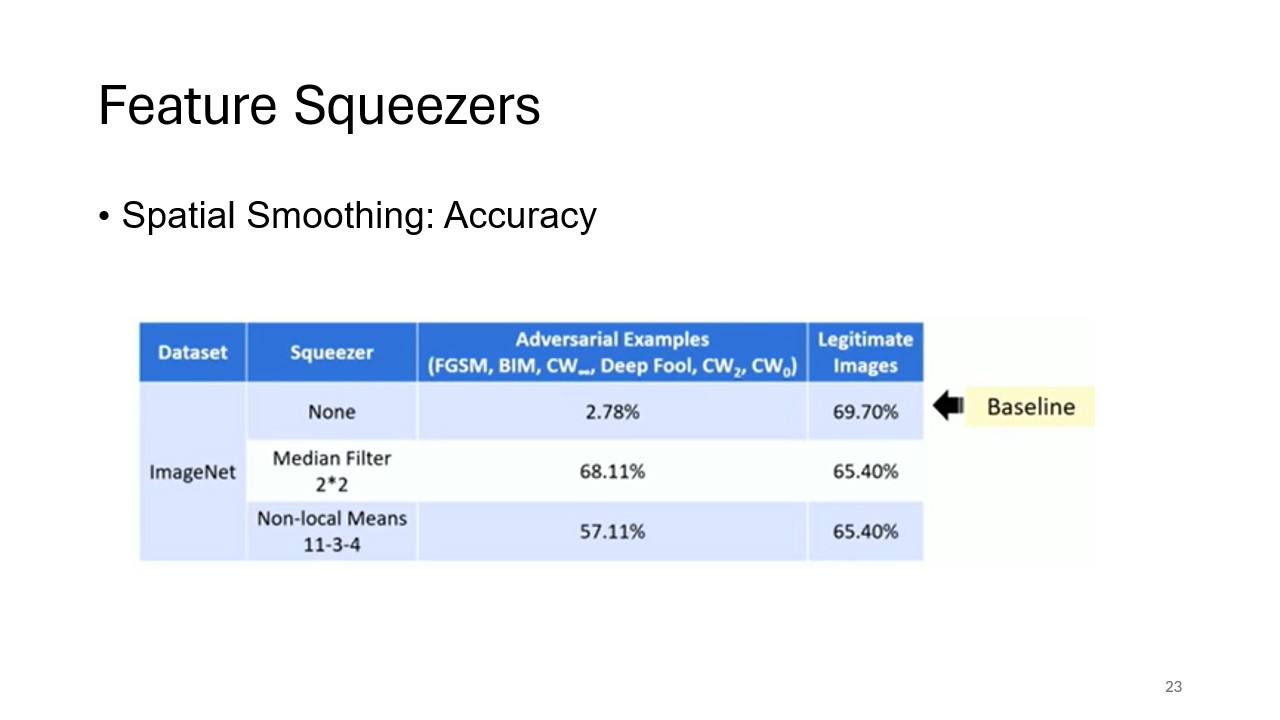
The slide evaluates the success of spatial smoothing methods, such as median filtering and non-local means smoothing, in defending against adversarial attacks. It presents data demonstrating the method’s ability to maintain classification accuracy despite adversarial perturbations.
Experimental Setup

This slide outlines the experimental design used to test feature squeezing. The datasets (MNIST, CIFAR-10, ImageNet) and adversarial attack methods (FGSM, BIM, DeepFool, JSMA, Carlini-Wagner) are described, along with the models used for testing (7-layer CNN, DenseNet, MobileNet).
Detection Evaluation

This slide evaluates the effectiveness of feature squeezing in mitigating adversarial attacks. Feature squeezing is shown to reverse adversarial perturbations in many cases, ensuring that the classifier’s predictions are not compromised by subtle input alterations.
Adversarial Threat Models

The two types of adversarial threat models—oblivious and adaptive adversaries—are explained here. Oblivious adversaries lack knowledge of the detection framework, while adaptive adversaries have full knowledge of both the target model and the detection methods, making them more difficult to defend against.
Detection Success for MNIST
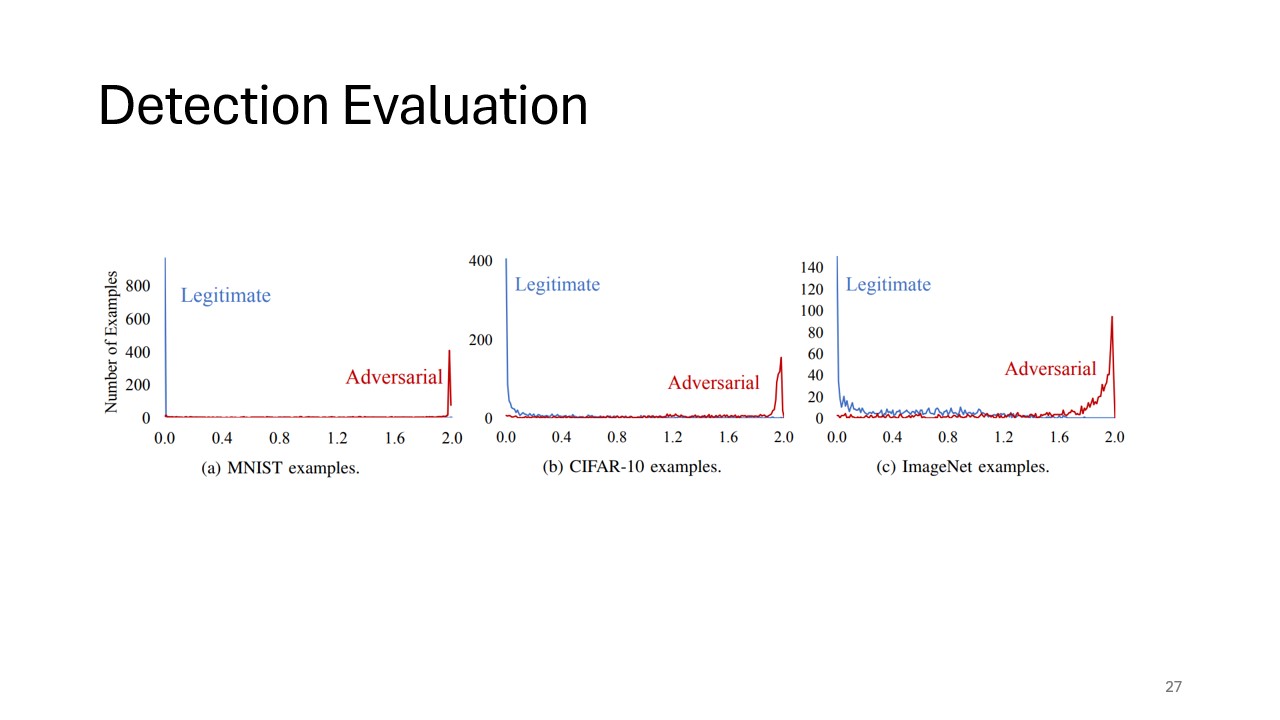
This slide presents the results of feature squeezing on detecting adversarial examples in the MNIST dataset, showcasing the success of the technique across different adversarial attacks.
Aggregated Detection Results
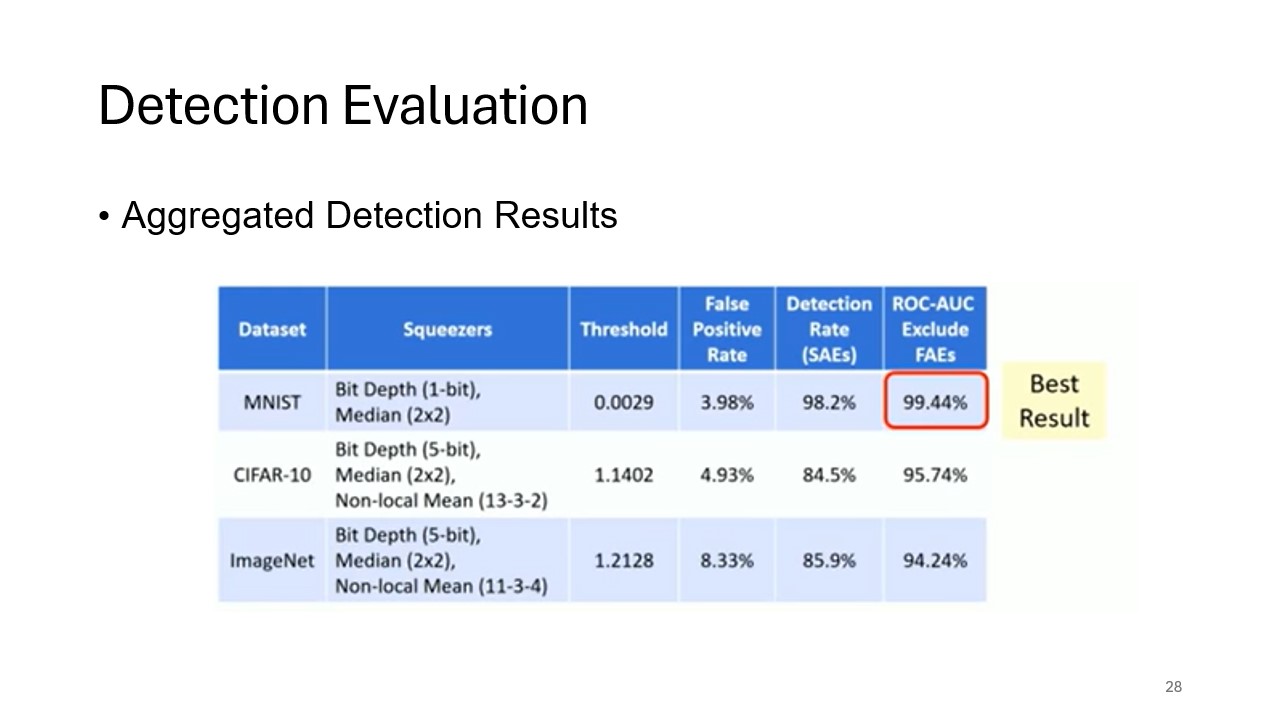
This slide consolidates the detection results across various datasets and attack types, demonstrating the broad applicability and effectiveness of feature squeezing in mitigating adversarial examples.
Adaptive Adversary Results

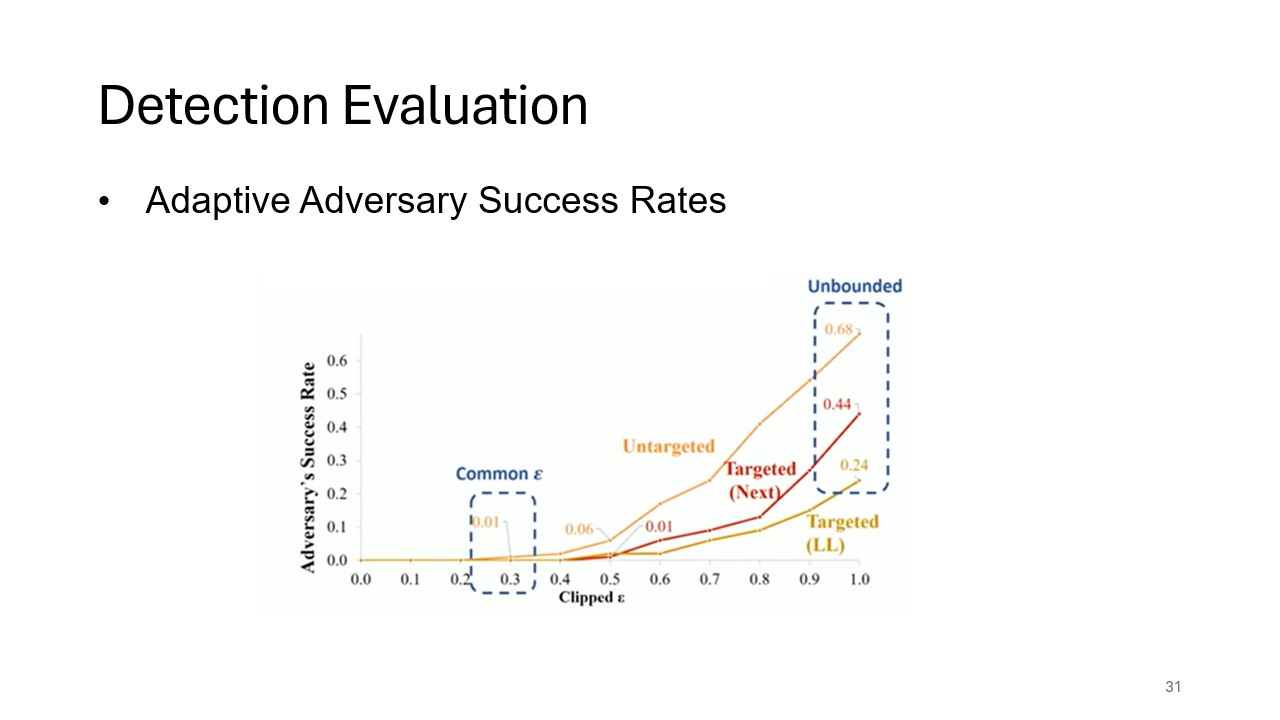
Here, the success rates of adaptive adversaries, who have full knowledge of both the model and the defense techniques, are analyzed. These adversaries present a tougher challenge, and this slide outlines their success in evading feature squeezing detection.
Randomization as a Defense
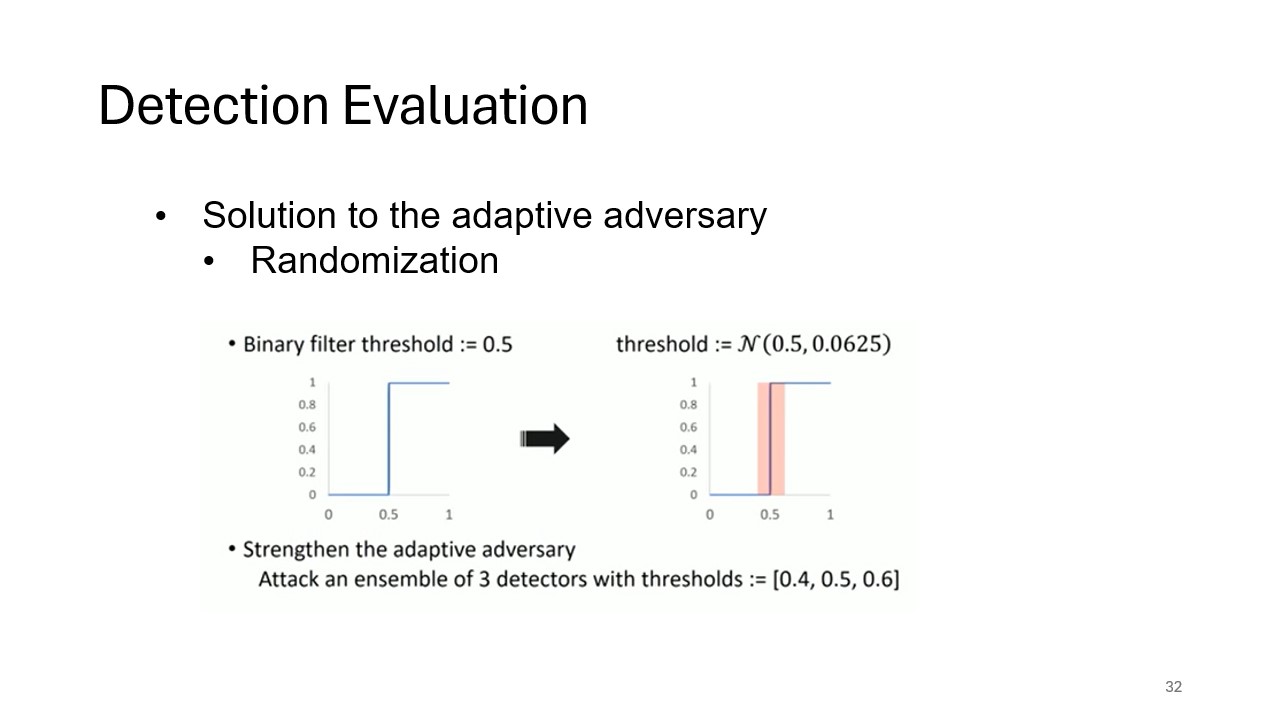
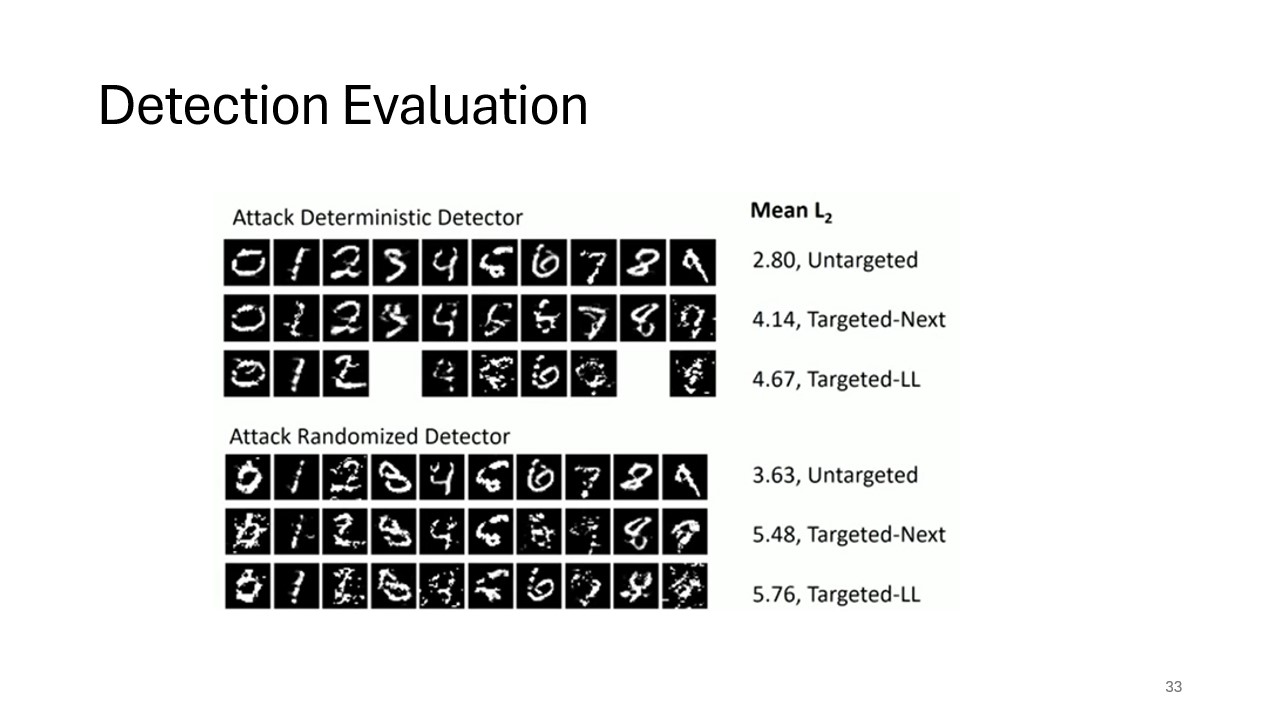
This slide introduces randomization as a potential solution to counter adaptive adversaries. By adding randomization to the detection process, the model can increase unpredictability, making it harder for adversaries to craft successful attacks.
Limitations

This slide outlines the limitations of feature squeezing. The technique has only been tested on MNIST, not on larger, more complex datasets like CIFAR-10 and ImageNet. Additionally, a single threshold is applied across different squeezers, which may limit its adaptability to different attack types. The computational cost can also rise significantly when using advanced models like autoencoders.
Summary

The slide summarizes the key findings of the presentation. Feature squeezing provides a simple yet effective defense mechanism for detecting adversarial examples in deep neural networks. By reducing the search space available to adversaries and combining feature vectors, feature squeezing offers a robust, computationally efficient way to enhance model security.
Discussions
Discussion 1: Do you think this method can produce the same results for real-time adversarial examples?
-
The presenter proposed that you might have to get all preprocessing the same size and choose the best window size before running.
-
Group 6 suggested that the Gaussian mean smoothing depends a lot on the window size and that finding the perfect window size would be impossible in real time.
Discussion 2: What are possible applications where the proposed method can be used?
-
Groups 1 and 4 said it could be used for any sort of facial or image software, or to automate driving.
-
The presenter added that it is used in many audio applications as well as biomedical systems.
Questions
Q1: Group 6 asked: How does bit reduction guarantee important information is not lost?
Simple smoothing works if the sample is not too complicated. If features are complicated or include multiple classes, problems can happen.
Q2: Group 8 asked: Do you have to do it for every data point?
You have to do it for the input change and apply preprocessing to the input, not changing parameters of the deep network.
In real time, you have to process every frame; is this expensive? In real time it is very expensive, as it is specific to these datasets.
Q3: Group 8 asked: Did you come across applying this technique in sequential modeling or signal processing?
In signal processing, you also apply smoothing; signals usually have outliers, so this smoothing works well for this but the names are different.
Changing this to affect adversarial changes in signals is possible but difficult in terms of recognition; probably won't change accuracy that much. Signal processing is complicated.