AI Psychiatry: Forensic Investigation of Deep Learning Networks in Memory Images
Authors: David Oygenblik, Carter Yagemann, Joseph Zhang, Arianna Mastali1, Jeman Park, Brendan Saltaformaggio
EE/CSC 7700 ML for CPS
Instructor: Dr. Xugui Zhou
Presentation by group 3:Zhiyong Sui (Presenter), Cheng Chen
Summarized by Group 7: Rishab Meka, Bharath Kollanur
Presentation date: September 18, 2024
Presentation slides:
AI Psychiatry: Forensic Investigation of Deep Learning Networks in Memory Images
Introduction
This presentation explores the forensic analysis of deep learning models using a novel technique called AiP (AI
Psychiatry). AiP is designed to recover machine learning models from memory images, which is critical for
investigating models that have been compromised or attacked. This process is especially important for understanding
models in production environments. AiP supports popular frameworks such as TensorFlow and PyTorch and has
demonstrated 100% accuracy in recovering models from memory for further analysis.
ML Model

This slide presents different types of attacks on machine learning models commonly used in autonomous vehicles.
Attacks using Pattern, Pixel, Patch, and Watermark illustrate how traffic signs are manipulated during
training for self-driving cars. These adversarial attacks aim to subtly alter the input data to trick the model into
making incorrect predictions, which could lead to safety-critical failures in real-world applications.
ML Model Vulnerabilities

Machine learning models are often targeted through various attacks, including data poisoning, adversarial examples,
and backdoor attacks. In data poisoning, attackers introduce malicious data during training, which compromises the
integrity of the model. Similarly, backdoor attacks involve embedding hidden triggers that can later cause the model
to make incorrect predictions. AiP helps identify these vulnerabilities by allowing forensic analysts to inspect and
understand how these malicious inputs influence the model’s predictions. By recovering models directly from memory,
AiP bypasses the need for access to original training data or binaries.
Understanding Vulnerabilities: From Benign to Compromised Machine Learning Models
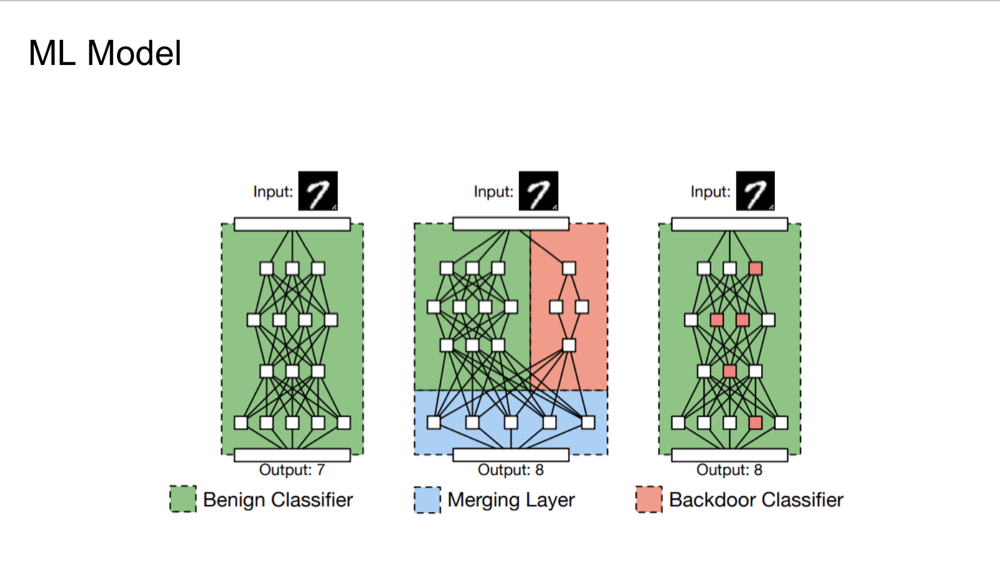
The slide illustrates three configurations of a machine learning model, showcasing the progression from a benign
classifier to potentially compromised versions through the integration of malicious elements. The first diagram
displays
a typical benign classifier processing an input to produce an output. The second introduces a merging layer,
depicted in
orange, symbolizing how a backdoor or malicious modification could be seamlessly integrated into the standard model
structure, subtly altering its output. The third diagram shows a backdoor classifier with direct modifications to
the
architecture, highlighted in red, indicating the nodes where the backdoor mechanism is incorporated, also affecting
the
model’s output. This visual representation emphasizes the susceptibility of machine learning models to subtle and
harmful modifications that can significantly alter their behavior, underscoring the critical need for robust
security
measures in their deployment.
Cross-Regional Risks: Propagation of Backdoors in Machine Learning Models
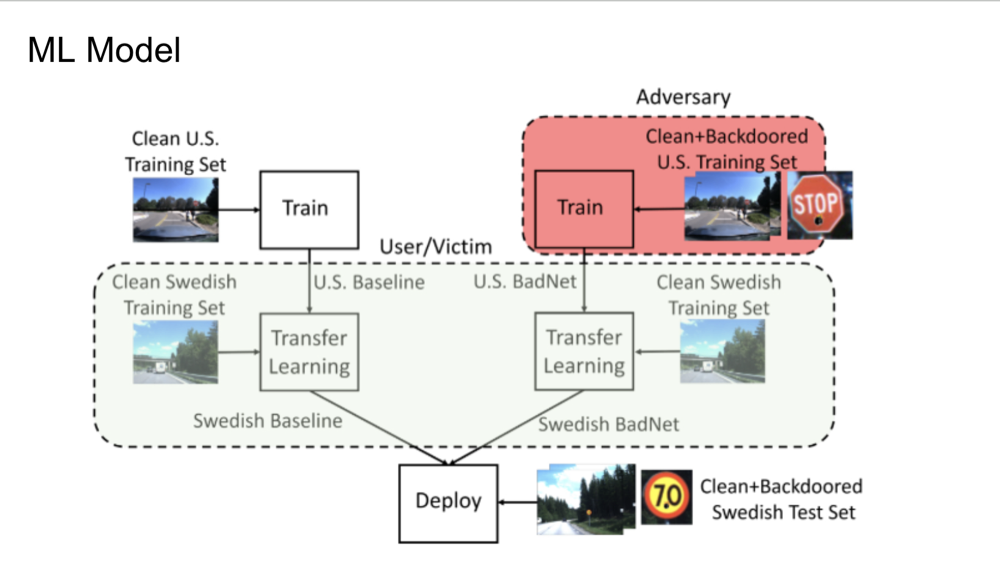
This slide demonstrates the impact of backdoored training data on machine learning models, focusing on the
transition of
training and deployment across U.S. and Swedish datasets. Initially, a model is trained with a clean U.S. training
set,
while an adversary simultaneously trains a compromised model using both clean and backdoored U.S. data, resulting in
a
model dubbed “U.S. BadNet.” Both the clean and compromised U.S. models undergo transfer learning with a clean
Swedish
training set, producing a benign “Swedish Baseline” and a potentially malicious “Swedish BadNet.” This process
highlights how backdoors introduced in the training phase can propagate to different regional models, underscoring
the
critical importance of rigorous testing against both standard and manipulated inputs to ensure the deployed models’
security and integrity in varied environments.
Abstract

AiP is a memory forensic technique that recovers machine learning models from both main memory and GPU memory,
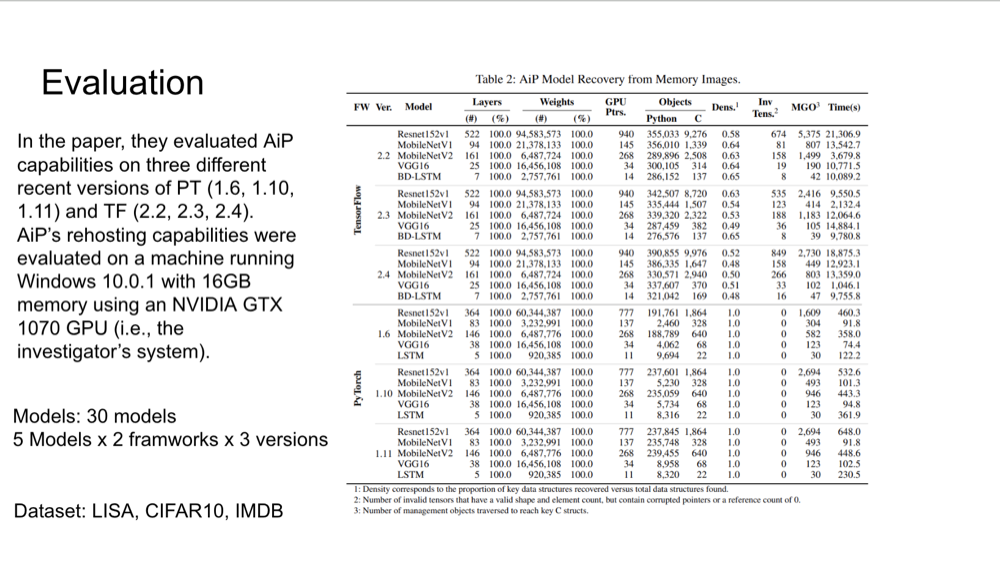
allowing investigators to inspect the model's internal workings. This method has been evaluated across three
versions of TensorFlow and PyTorch using datasets such as CIFAR-10, LISA (traffic sign dataset), and IMDB (movie
review dataset). AiP successfully recovered 30 models with 100% accuracy, enabling detailed white-box testing to
analyze the model's vulnerabilities. The approach supports both black-box and white-box testing environments,
providing forensic investigators with the tools needed to perform a comprehensive analysis of deep learning systems.
Challenges in Model Recovery

There are several challenges in recovering machine learning models from memory. Many models are protected with
encryption or are closed-source, making it difficult to retrieve them directly. Additionally, models that undergo
online learning continuously update their weights, leading to unique, environment-specific models. AiP addresses
these challenges by focusing on recovering models from memory images rather than requiring direct access to source
code or encrypted binaries. The technique allows investigators to recover models in a way that preserves the
integrity of the unique, real-time weights and structures found in production environments.
AiP Introduction
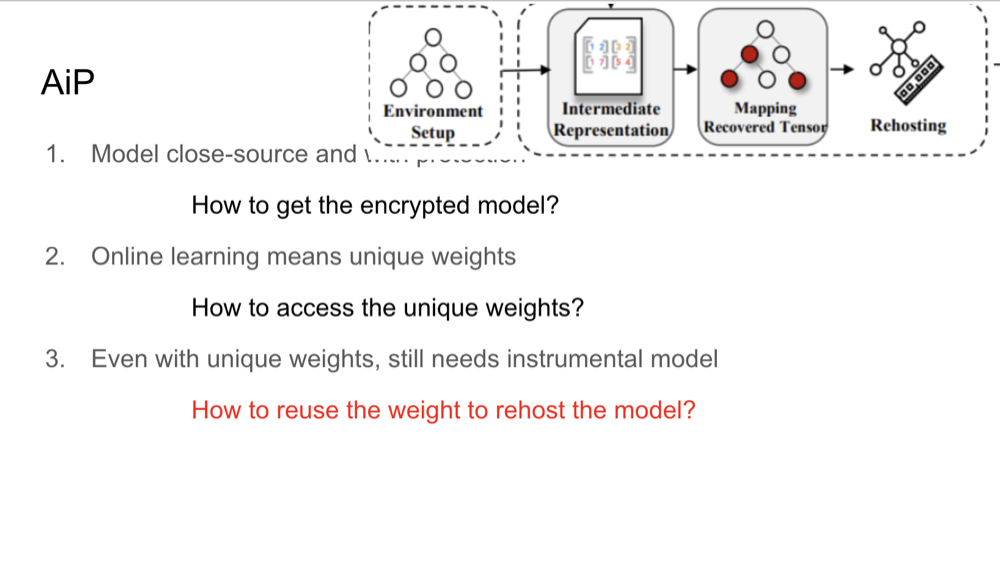
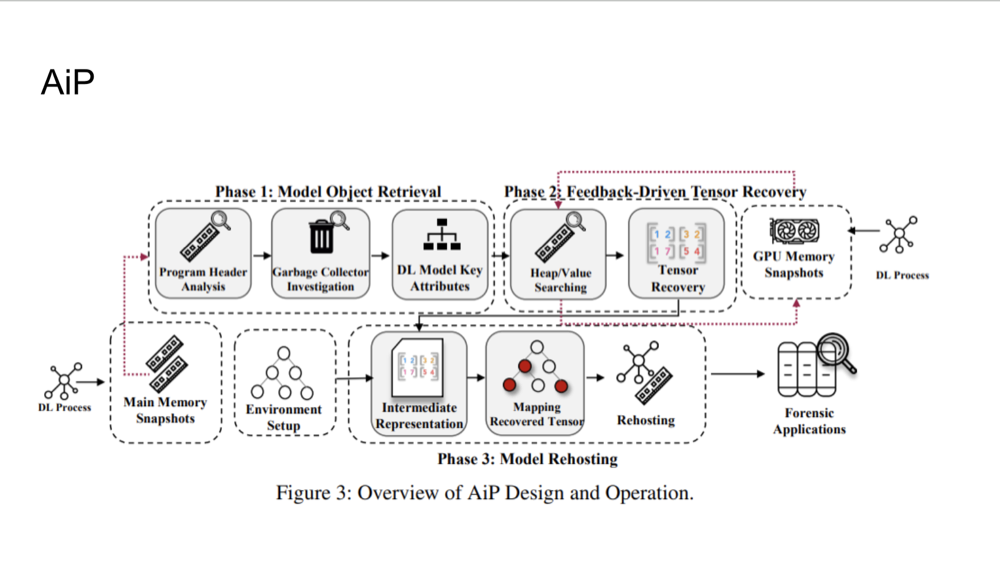
AiP enables the recovery of machine learning models, including those protected by encryption or undergoing
real-time learning updates (online learning). Once recovered, these models can be rehosted for forensic analysis in
a controlled environment. AiP operates by navigating both the CPU and GPU memory spaces to locate and extract key
deep learning data structures, including tensors and model weights. This process allows investigators to analyze how
the model was functioning at the time of failure or attack, providing valuable insights into the nature of the
vulnerability.
Phase 1: Model Object Retrieval
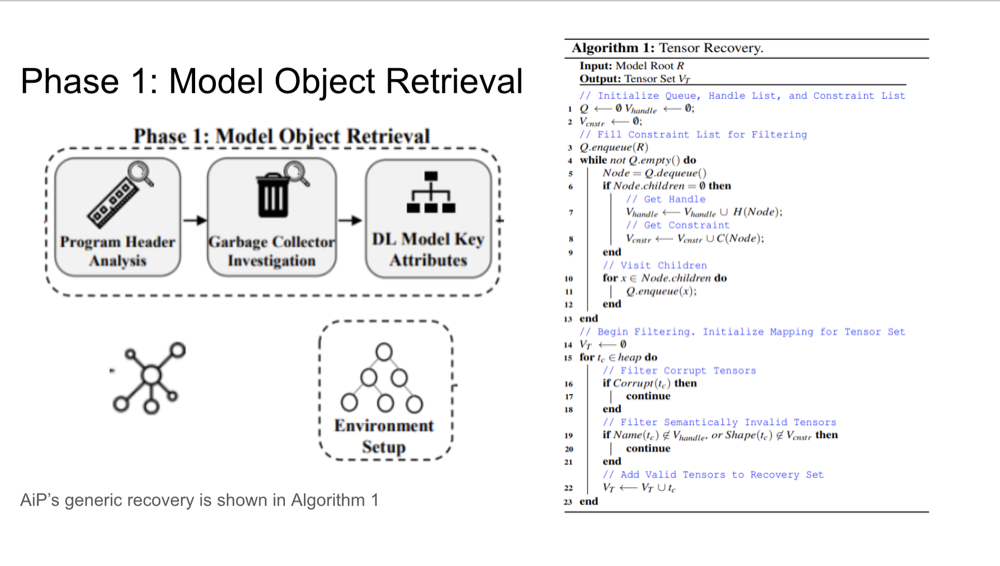

The first phase of AiP involves searching for directed acyclic graphs (DAGs) in memory, which represent the
structure of the deep learning model. DAGs are key to understanding how computations flow through the model. AiP
identifies the root objects in memory, which point to other components of the model, such as layers and tensors.
This process allows AiP to build a complete map of the model’s architecture, which is essential for further
analysis. Once the model object is retrieved, it serves as the foundation for recovering all related tensors and
computations.
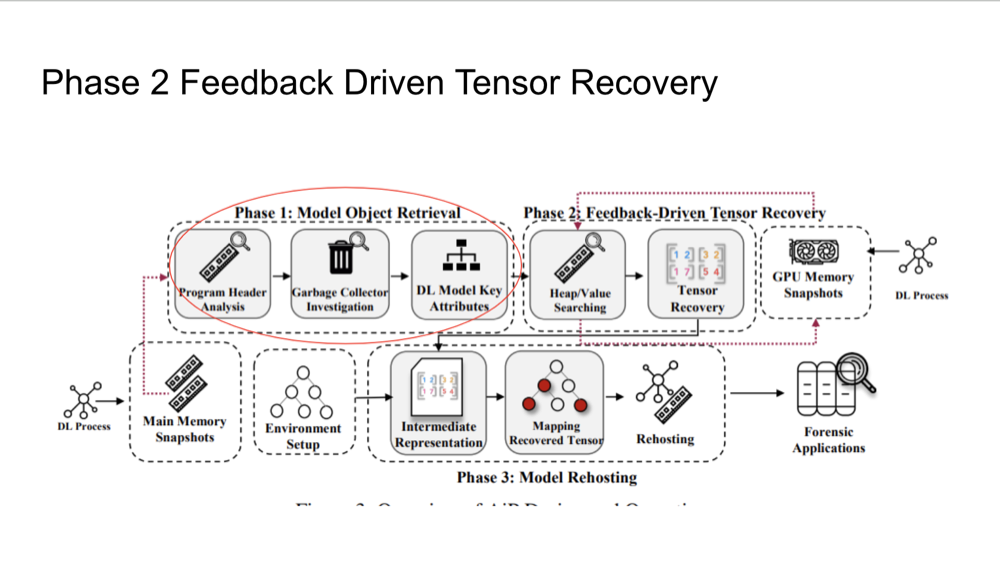
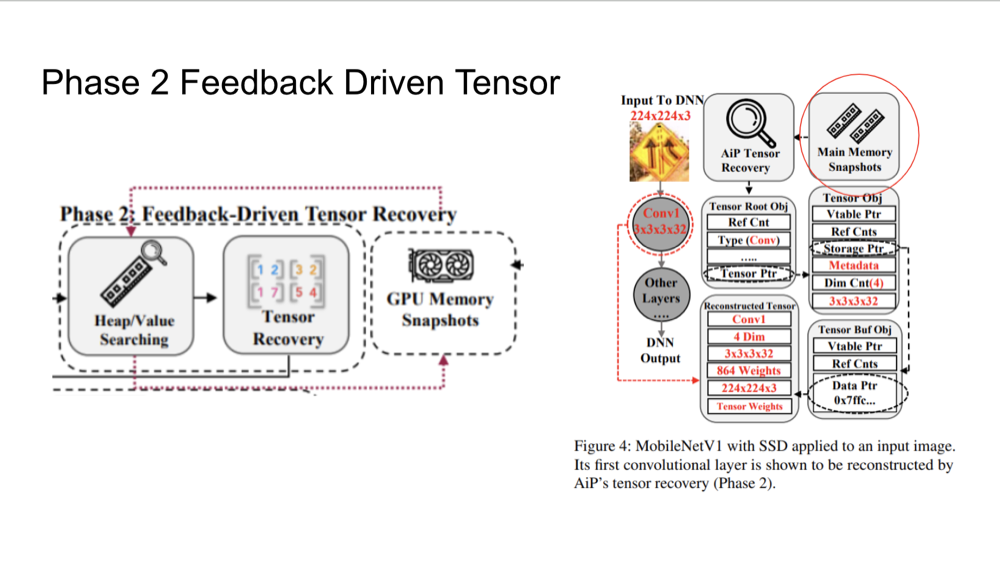
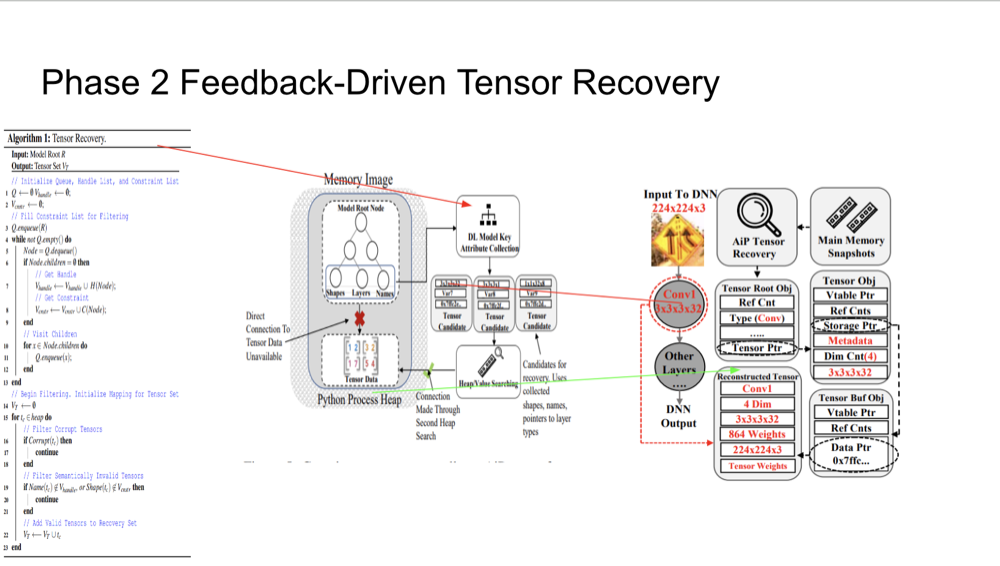
Phase 2: Feedback-Driven Tensor Recovery
Phase 3: Model Rehosting and Reuse
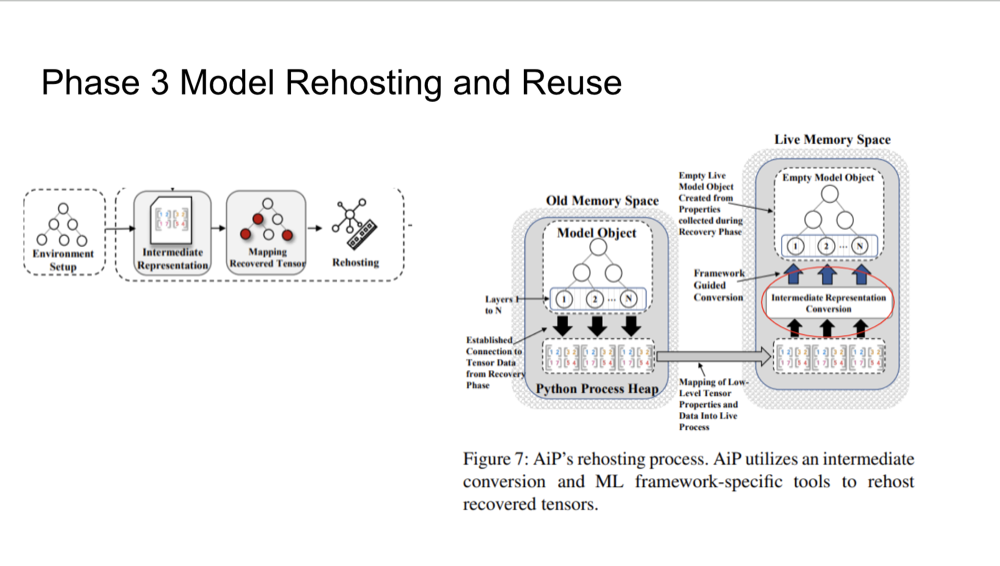
After retrieving tensors and other key components, AiP rehosts the model in a live environment for analysis. This
step allows forensic investigators to perform white-box testing, where they have full access to the model's internal
structure and behavior. The recovered tensors are transformed into an intermediate representation to ensure
compatibility with the framework in use, enabling detailed analysis even if the model was initially secured by
encryption or other security measures.
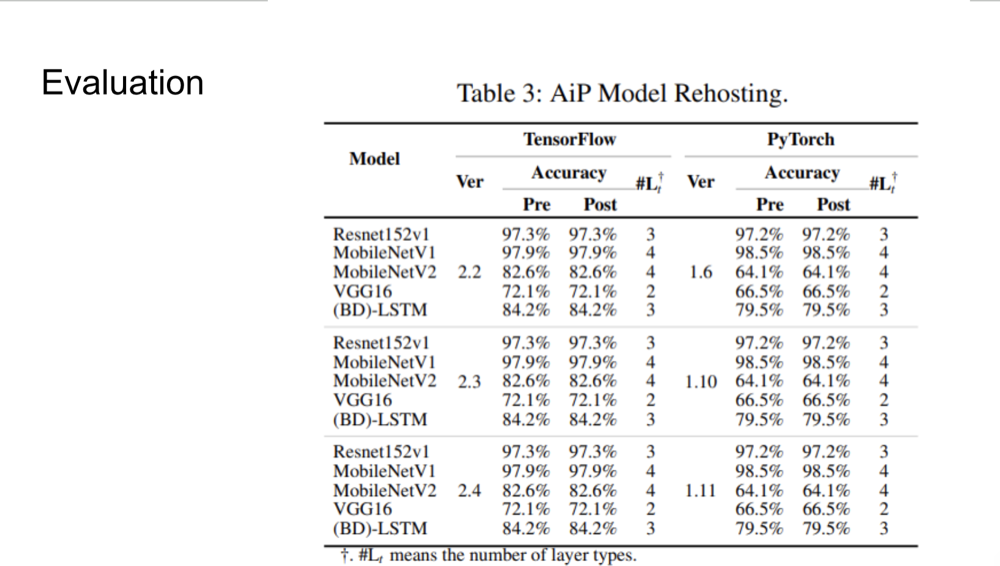
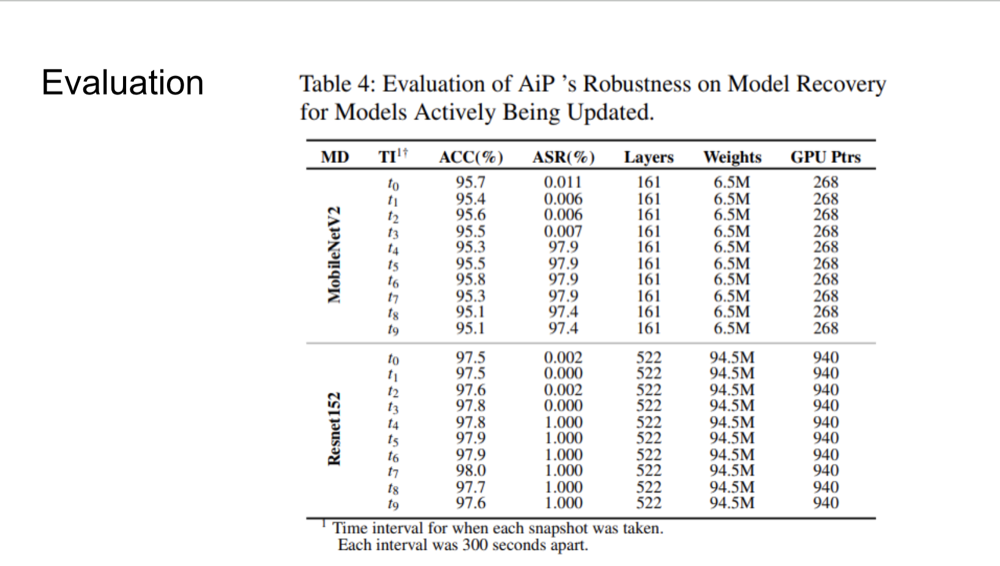
Evaluation
Simulation Setup

A simulation compares two different forensic investigation methods: black-box analysis using AEVA (performed by Bob)
and white-box analysis using AiP (performed by Alice). The simulation involves a self-driving car’s model being
gradually poisoned with adversarial examples, introducing backdoors into the model. AiP is used to recover the model
and detect these backdoors, highlighting its strength in identifying subtle backdoors that black-box methods may
overlook.
Simulation Findings

The simulation results indicate that Alice, using AiP and white-box analysis, successfully detected all backdoors
embedded in the model with 100% accuracy. In contrast, Bob’s black-box approach failed to detect any backdoors. These
findings underscore AiP's effectiveness in forensic investigations, particularly in scenarios involving sophisticated
attacks like backdoor insertion.
Contributions of AiP

AiP offers a significant tool for forensic analysis, especially for models undergoing continuous updates. Its ability
to recover and rehost models for white-box analysis surpasses traditional black-box methods, which often struggle to
detect subtle vulnerabilities. By providing comprehensive access to the model's internal structure, AiP enables more
thorough investigations into model behavior and vulnerabilities.
Limitations

While AiP is a powerful forensic tool, it has limitations. It may not perform effectively on models that have been
heavily optimized or obfuscated, such as those using quantization techniques. Moreover, secure enclaves and trusted
execution environments (TEEs) can inhibit memory acquisition, restricting AiP’s ability to recover models in certain
cases. In highly protected environments, forensic investigators may need to employ additional techniques alongside AiP
to achieve a complete analysis.
Questions
Q1. Why is there a disparity in the ASR error rate? (Group 1)
The disparity in the error rate typically arises in scenarios where a model behaves differently under
certain conditions due to a specific trigger—an event or condition that causes a significant change in the model’s
performance.
Q2. To recover tensors instead of deterministic approaches, is it possible to use LLM's to recover
the tensors? (Group 8)
No, LLMs do not have enough context and also there are too many tensors, making it impractical to use
LLMs for tensor recovery in this context.
Q3. Are some models harder to recover? (Group 8)
It totally depends on the ML framework. Some frameworks may have complex architectures or utilize
advanced security features that make model recovery more challenging.
Q4. Are they recreating the model from memory data? (Group 6)
They are reconstructing the model, not recreating it from the memory data. Reconstruction involves
piecing together model components from memory dumps to understand the model's architecture and functionality.
Discussion Questions
Q1. How can ML/DL models be reconstructed and rehosted for different use cases, such as mobile,
healthcare, or smart home devices?
Reconstructing ML/DL models for various use cases involves adapting them to different operational
constraints and environmental factors. For instance, in a smart home scenario, an alarm system might trigger
unexpectedly due to a hack. A snapshot of the memory at that time could allow a hacker to reconstruct the model and
uncover vulnerabilities.
Q2. What are the anti-forensic methods available for model reconstruction frameworks, as discussed
in this paper?
Anti-forensic methods that hinder model reconstruction include the use of ensemble networks and
increasing model complexity. As the size of the model increases, it becomes more challenging to reconstruct it quickly
and accurately, especially if the model uses techniques like ensemble learning, which can obscure the underlying data
patterns and operational logic.
Q3. Could this framework be exploited by hackers to extract models that companies intend to keep
secure from users?
Yes, while the framework is designed for forensic analysis and improving security, it also presents a
potential risk if exploited by hackers. Hackers could potentially use similar techniques to extract and analyze
proprietary models, especially if they gain access to memory dumps or can mimic the conditions under which the
forensic analysis is typically performed.