Informed Machine Learning – A
Taxonomy and Survey of Integrating Prior Knowledge into Learning Systems
Authors: Laura von Rueden , Sebastian Mayer , Katharina Beckh , Bogdan Georgiev , Sven Giesselbach , Raoul Heese , Birgit Kirsch , Julius Pfrommer , Annika Pick , Rajkumar Ramamurthy , Michal Walczak , Jochen Garcke , Christian Bauckhage , Member, IEEE, and Jannis Schuecker
For class: EE/CSC 7700 ML for CPS
Instructor: Dr. Xugui Zhou
Presentation by Group 9: Trevor Spinosa
Blog post by Group 5: Fozia Rajbdad
Link to Paper: https://arxiv.org/pdf/1603.06318
Research Contributions
It proposed an abstract concept for informed machine learning that clarifies its building blocks and relation to conventional machine learning.
It states that informed learning uses a hybrid information source that consists of data and prior knowledge, which comes from an independent source and is given by formal representations.
The main contribution is introducing a novel, first-of-its-kind taxonomy that classifies informed machine learning approaches.
The paper described available approaches and explained how different knowledge representations, such as algebraic equations, logic rules, or simulation results, can be used in informed machine learning.
|
Slide 02: Motivation |
|
|
|
Slide 2 explains the motivation behind the work, i.e., the challenges conventional machine learning faces. This includes data sacrifice, meaning most datasets are not labeled, which is required for supervised machine learning. Secondly, most of the model needs that are not explainable could not be trusted by experts, specifically where human lives are at risk, such as healthcare diagnostic and cure systems. |
|
Slide 03: Introduction to Informed Machine Learning |
|
|
|
Slide 3 describes informed machine learning as a framework that combines data-driven methods assisted with external formal knowledge sources. This contrasts with traditional machine learning, which solely depends on the data, cannot perform well with limited labeled data, and is constrained by domain. |
|
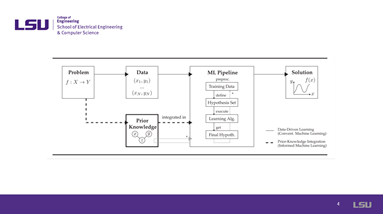
Slide 04: Block Diagram of the Proposed Method |
|
|
|
Slide 4 presents the information flow in informed machine learning. The informed machine learning pipeline requires a hybrid information source with two components: Data and prior knowledge. Conventional machine learning knowledge is used for data preprocessing and feature engineering, but this process is deeply intertwined with the learning pipeline (*). In contrast, in informed machine learning, prior knowledge comes from an independent source, is given by formal representations (e.g., knowledge graphs, simulation results, or logic rules), and is explicitly integrated. |


|
Slide 05: Knowledge Types |
|
|
|
The presenter explained the types of knowledge in this slide. Scientific knowledge in physics and biology is the primary source of knowledge in IML. The second source of knowledge is world knowledge, which is about the observable facts or relationships between the objects in an image. |
|
Slides 06 & 07: Knowledge Representation |
|
|
|
This slide discusses knowledge representation methods. These methods include equations represented by algebraic or differential equations specified by quantitative laws. Similarly, simulations are representations of models that simulate real-world scenarios. Moreover, knowledge is graphically represented mainly with the help of entities as nodes with edges. Besides, human feedback is significant for correcting a model while training it. The table in slide 07 demonstrated these knowledge representations. |
|
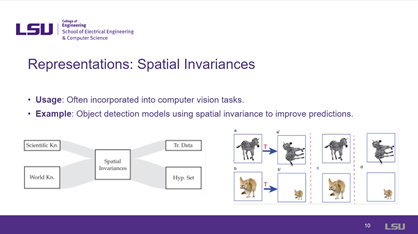
Slides 08-11: Representations |
|
|
|
From slides 8 to 11, knowledge representations are discussed. In slide 8, algebraic and differential equation representation is discussed, with an example of a physics-based constraint in models predicting movement or energy. Secondly, simulations have been discussed to address data scarcity by generating synthetic data such as autonomous vehicle simulation for several driving conditions. Spatial invariances are another form of knowledge representation that is more useful in computer vision applications such as object detection. Lastly, the representation of logic rules and knowledge graphs is discussed in the 11th slide. It formalized if and else statements that helped describe the reasoning, such as networked representations of features at nodes and their relationship. |
|
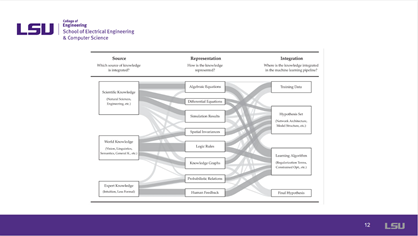
Slide 12: Taxonomy of IML |
|
|
|
This slide discussed the taxonomy of the IML. This taxonomy serves as a classification framework for informed machine learning and structures approaches according to the three above analysis questions about the knowledge source, knowledge representation, and knowledge integration. Based on a comparative and iterative literature survey, we identified elements representing a spectrum of different approaches for each dimension. The size of the elements reflects the relative count of papers. We combine taxonomy with a Sankey diagram in which the paths connect the elements across the three dimensions and illustrate the approaches we found in the analyzed papers. The broader the path, the more papers we found for that approach. Main paths (at least four or more papers with the same approach across all dimensions) are highlighted in darker grey and represent central approaches of informed machine learning. |
|
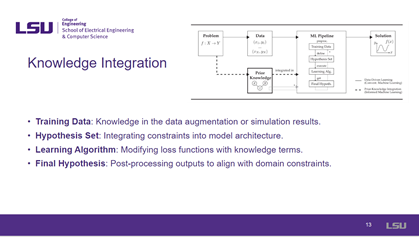
Slide 13: Knowledge Integration |
|
|
|
Knowledge integration is discussed in this slide 13. This interaction includes training data, a hypothesis set, learning algorithms, and a final hypothesis. Training data comprised of results obtained from data augmentations and simulations. Similarly, the hypothesis set includes contrast, and learning algorithms changed loss with knowledge terms. And post-processing, which contains outputs aligned with contraction, comes under the final hypothesis. |
|
Slides 14& 15: Integration into Training Data with Example |
|
|
|
This slide discusses knowledge integration into the training data, which could increase the data domain and help improve the model generalization. One example discussed is simulation-based augmentation, which is based on synthetic data and includes complex scenarios, such as the worst weather conditions in automatic car training. Bad weather is depicted in slide 15. |
|
Slide 16&17: Integration into Hypothesis Set and Learning Algorithm |
|
|
|
In slides 16 and 17, Integration into the hypothesis and learning algorithm are discussed, respectively. Integrating knowledge into the hypothesis helps the model capture the domain relationship and constraints, such as knowledge-guided layers. Similarly, a learning algorithm helps embed the knowledge directly into model optimization, such as physics-informed content that explains the laws of motion. |
|
Slides 18& 19: Knowledge-Based Loss Functions |
|
|
|
The presenter discussed knowledge-based loss functions in slides 18 and 19. These functions integrate knowledge into the learning process by adding constraints. This addition helps to enforce the model to recognize the known rules and aid robustness. One such example is the PINNs, carefully designed to avoid over-restriction. Moreover, the knowledge-based loss term is defined with the help of the equation shown in slide 19. This objective function offered is label-free knowledge-based supervision. |
|
Slides 20: Physics-Informed NN Example |
|
|
|
In slide 20, an example of a physics-informed neural network is explained. This example used a simulation of the model, which learned from physical dynamics such as fluids governed by the Navier-stoked equations. Moreover, a physics-based loss term is added that disciplines output violating physical laws such as energy conservation or mass. |
|
Slide 21: Integration into Final Hypothesis |
|
|
|
Here, integration into the final hypothesis is discussed, which involves validating and refining the model's output and ensuring the alignment of the established rules with significant improvements in safety and reliability. One example of such an approach is filtering predictions to remove violations of standards such as legal and safety regulations in critical applications. |
|
Slides 22 & 23: Limitations and Future Works |
|
|
|
The main limitations of the proposed method are its transferability, i.e., the ability to apply the model to other domains, and its scalability, specifically for large datasets. Besides, it is balanced between the knowledge-driven and data-driven elements. Extension to the proposed method in the future could represent more complex knowledge and application of IML in other fields. |
|
Slides 24: Teamwork |
|
|
|
This slide acknowledges the other team member who assisted the presenter in understanding concepts and formatting slides/discussion questions. |
|
Slides 25 & 26: Questions and Discussions |
|
|
|
The last two slides showed the questions and discussion from the audience the questions and answers. |



















Discussions:
1.
What are some potential risks of relying
on domain-specific knowledge in machine learning models?
Group 1 explained that with domain-specific knowledge, the model must present natural information, as prior knowledge would be better.
Group 6 explained that combining rule-based learning in training data and putting knowledge in the loss function would be much better.
2.
In what situations might integrating
knowledge into the learning algorithm be more beneficial than into the training
data?
Group 4 discussed that training the model with a lot of data may not work, but changing the data may add more feature points or shuffle the data.
3.
How could knowledge validation at the
final hypothesis stage help build public trust in AI systems, especially in
healthcare or autonomous driving?
Group 7 Proposed Generative AI would be helpful and better than predictive AI.