"Why Should I Trust You?” Explaining the Predictions of Any Classifier
Authors:Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin
For class EE/CSC 7700 ML for CPS
Instructor: Dr. Xugui Zhou
Presentation by Group 8:Pacco Tan
Time of Presentation:10:30 AM, Monday, November 11, 2024
Blog post by Group 4: Betty Cepeda, Jared Suprun, Carlos Manosalvas
Link to Paper:
https://dl.acm.org/doi/abs/10.1145/2939672.2939778
Summary of the Paper
The paper discusses the importance of understanding the reasons behind machine learning model predictions. This
understanding is crucial for building trust in the model, especially when relying on its predictions for
decision-making. The authors propose LIME, a technique that explains model predictions by learning a simpler,
interpretable model locally around the prediction.
They also introduce a method to select representative individual predictions and their explanations to provide a
concise and informative overview of the model's behavior.
The effectiveness of these methods is demonstrated through various experiments, including simulated and
human-subject studies, in scenarios that require trust in machine learning models. These scenarios include
deciding on the reliability of a prediction, selecting between different models, improving untrustworthy models,
and identifying potential biases or limitations in the model.
Slide 1 & 2: Introduction & Motivation


The initial slides introduce the presentation topic: Explaining predictions of any classifier. The motivation for this research is mainly to create a framework to generate model trust.
The presentation delves into why trust in ML decisions is essential,
especially for high-stakes applications.
Slide 3: Desired Characteristics for Explainers

The desired characteristics for an ML explainer are outlined here. It emphasizes the need for local fidelity,
model-agnostic methods, and a global perspective, underscoring that an explainer should offer understandable insights that generalize well across models.
Slide 4: Interpretable Data Representations
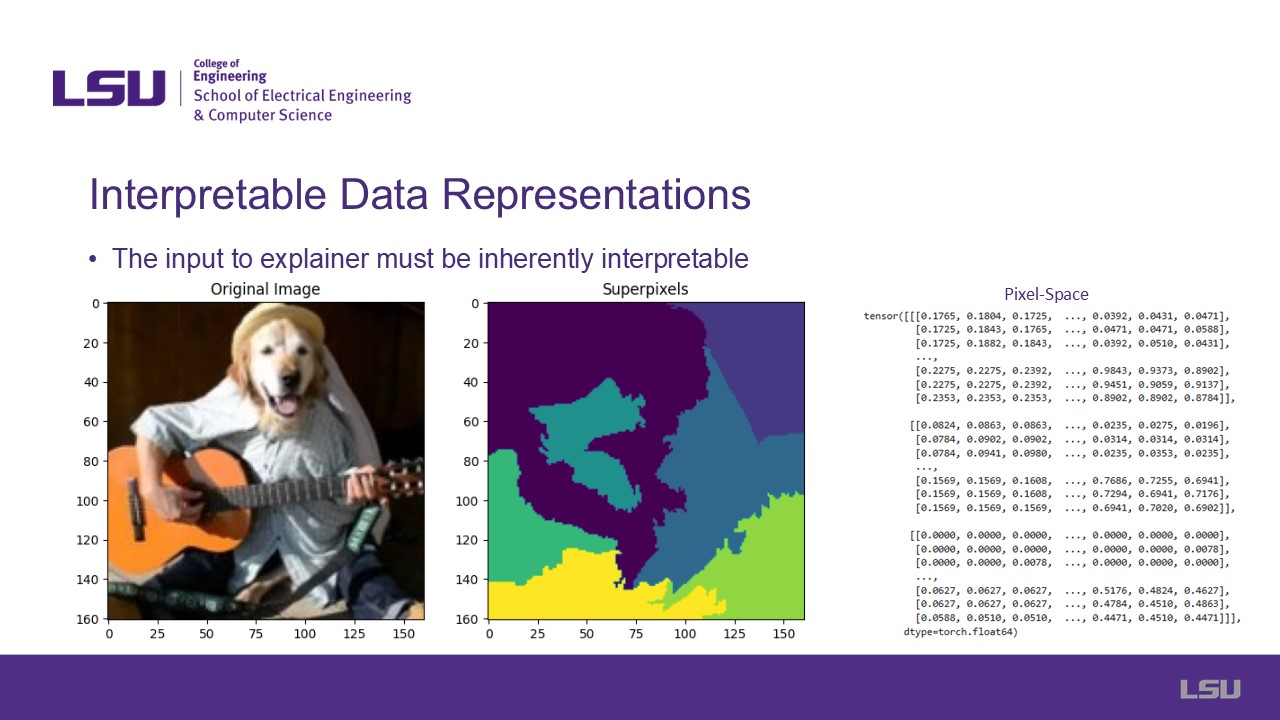
This slide addresses the concept of interpretable data representations, essential for understanding model
behavior.
Slide 5: Fidelity and Interpretability

The concepts of fidelity and interpretability are introduced. Fidelity refers to the accuracy of the
explanation, while interpretability involves the simplicity and comprehensibility of the explanation. Both concepts are key for creating reliable model explainers.
Slide 6: Experimentation

This slide presents the experimental approach the authors took to generate an "Explainer" algorithm.
An algorithm is shown.
Slide 7: Submodular Pick(SP) for explaining Models

This slide introduces the Submodular Pick algorithm, explaining how this algorithm helps in the process of finding the best set covering features.
Slide 8 & 9: Results of Explainerand SP-Lime

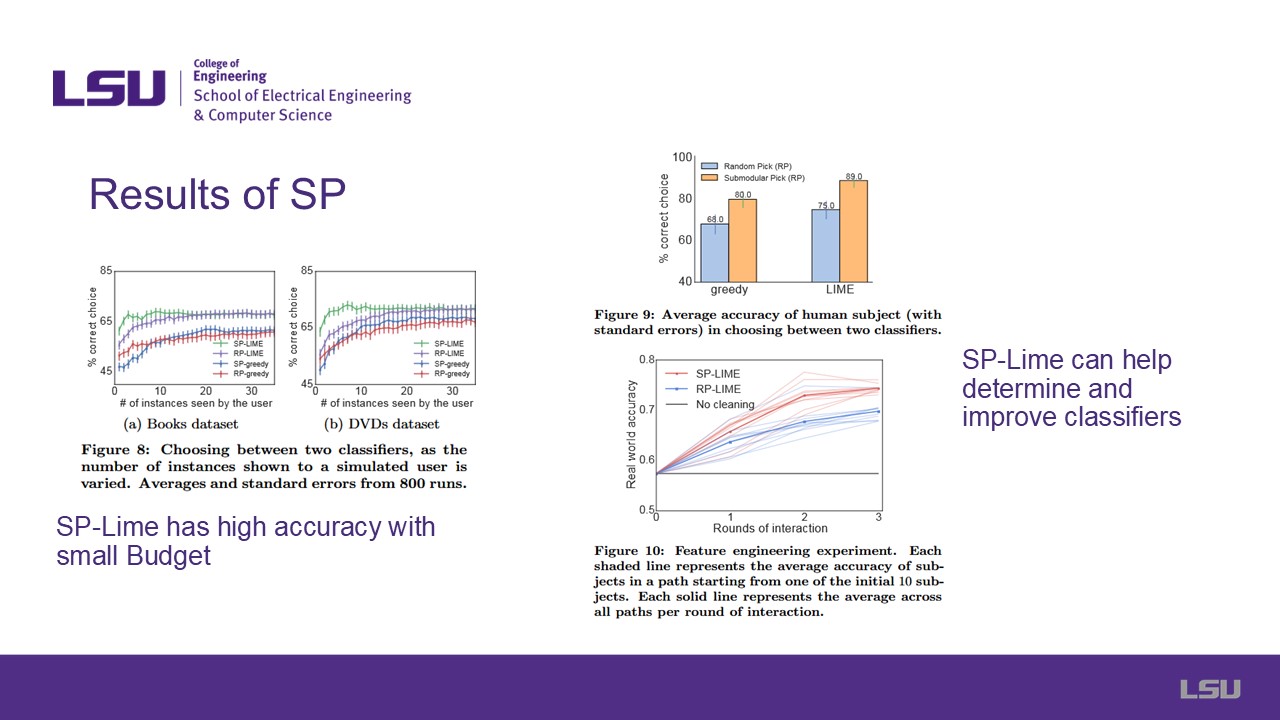
Results are shown for diferent methods of generating explanations.
Random generation, Parzen Generation, Greedy Generation and LIME are all compared using the Recall Metric in different Datasets.
SP-LIME was shown to have a better accuracy with a small Budget, showing that it can help determine and improve classifiers
Slide 10: Limitations

The limitations of the proposed method are explained in this slide . Issues such as the intractability of
capturing every detail of complex models, reliance on interpretable representations, and challenges in selecting
optimal sampling strategies and distance measures.
Slide 11: Teamwork

This slide emphasizes teamwork and collaborative contributions in the presentation.
Slide 12: Discussion Questions

Several discussion questions are presented
Slide 13: References

The final slide lists references for further reading.
Discussion
Discussion 1: How can we replace the interpretable representation so that it is more flexible?
Group 6 suggested use of LLMs to intepret the pixels. LLMs traditionally interpret features using words, so by having words label
the pixel groups (such as "guitar" for the pixels composing the neck of guitar), we can establish the same benefits of interpratability
while also becoming more easily understandable for humans.
The presenter and teammate (Group 8) mentioned it was a good idea but some tradeoffs include the introduction of reliance on LLMs.
In addition, the LLM itself is generally an ambiguous black box approach which is part of the challenge this paper aims to address.
Group 6 member again remarked that the benefit of human intepretability might just be enough to counter the lack of accuracy introduced.
Discussion 2: What are some potential complexity measures or ways to better approximate interpretability?
N/A
Discussion 3: What are other classes of models that could be used for explanation?
Group 5 suggested using a model-specific approach instead of the utilized model-agnostic black box approach.
Group 6 and the presenter remarked how that could be sufficient but is important to note the dependability on the specific inputs and
outputs cause the results to be a certani way, moreso than the model itself.
Discussion 4: Are there alternative perturbation strategies that may perform better?
N/A
Questions
Q1: Dr. Zhou asked for a brief and simple explanation of how LIME works?
The presenter mentions that the method starts with local fidelity, meaning it looks at one instance at a time. They
have a single image which is sampled around it, obtaining other similar and smaller images related to the original
one. The model then uses the original input image and the sampled images for training; it computes a classification
prediction of the image and analyzes what the outcome is. Finally, it fits a simple linear regression network to
understand the data. In summary, it attempts to use simpler versions of the input data to classify it.
Q2: Dr. Zhou asked how to understand the interpretability of the model.
Depends on how we interpret representation, which is one of the limitations of the paper. Super pixels are just
patches of the image that the model chooses to use. This is useful for some applications, but not for others.
Q3: Group 5 asked if the explainability is based on the feature or the model. How does the model obtain the
features.
For text, this happens before embedding it during hot vectoring. For images, they come from a superpixel algorithm.
Q4: Group 5 asked how interpretability and explainability are different.
They are similar, but present small differences. Intepretability has more to do with how good to interpret the
representation, making it easier to understand. Explainability is how easy to explain.
Q5: Group 6 asked how noise is being injected into the system
The presenter mentions that the authors are using a mask on top of the image. Given some inputs, it randomly picks
some patches and then perturbs the image. Sampling is not done with noise, it is simply choosing which patches to
account for. It is explained also as blacking out part of the input image. Many methods are available for this
matter.