Robust Physical-World Attacks on Deep Learning Visual Classification
Authors: Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song.
Presentation by: George Hendrick
Blog post by: Obiora Odugu
Link to Paper: Read the Paper
Summary of the Paper
This paper introduces RP2 (Robust Physical Perturbation), a novel algorithm that generates physical adversarial perturbations capable of deceiving deep neural network (DNN) classifiers under real-world conditions. The authors target road sign classification, demonstrating how small, graffiti-like stickers applied to stop signs can mislead DNNs into classifying them as different signs (e.g., Speed Limit 45). These attacks remain effective despite environmental changes in lighting, angle, and distance. The study proposes a two-stage evaluation—lab and drive-by tests—to simulate real-world scenarios. Results show up to 100% targeted misclassification in lab tests and 84.8% in field tests. The paper also extends the attack to general objects like microwaves, which are misclassified as phones. By highlighting vulnerabilities in vision-based AI systems, this work emphasizes the urgent need for robust defenses against physical-world adversarial examples in safety-critical applications like autonomous driving.
Presentation Breakdown

Motivation
This slide explains the motivation behind the study. It highlights that deep neural networks, despite their success, are vulnerable to small, human-imperceptible perturbations. The authors aim to explore how such adversarial examples behave in the physical world using road signs as the test case

Introduction
Here, the authors justify the use of road sign classification: Road signs are simple yet critical. They appear in dynamic, uncontrolled environments. Misclasification can pose serious safety threats. This sets the stage for understanding real-world adversarial threats.

Background
This slide provides a foundational understanding: Digital adversarial examples (e.g., Fast Gradient Method by Goodfellow). Early work showing that adversarial images can fool models even when printed and viewed through a camera.

Background
This slide continues the literature review: Progression from synthetic to 3D-printed physical adversarial examples. Other works using perturbations in wearable items like eyeglasses. Notably, detectors (as opposed to classifiers) were found to be resistant, highlighting a gap in attack effectiveness.

Contributions of the Paper
This slide outlines the core contributions: Introduction of RP2: an algorithm that generates robust physical perturbations. Evaluated against two classifiers: LISA-CNN and GTSRB-CNN. Proposal of a two-stage evaluation methodology (lab + field tests).

Method
The slide discusses real-world issues that adversarial attacks must survive: Changes in viewpoint and lighting. Constraints in applying perturbations. Fabrication and sensor errors.

Method
This slide introduces the RP2 algorithm: It uses an optimization approach to generate perturbations. The loss function is modified to account for physical changes like rotation and lighting variations.

Method
Here, the use of a mask to constrain perturbations is discussed: The mask helps make perturbations appear as natural graffiti. Vulnerable regions are targeted using L1 and L2 optimization.

Experimental Evaluation
This slide summarizes the evaluation setup: Attacks are tested on stop signs and general objects (e.g., microwave). Models used: LISA-CNN and GTSRB-CNN.

Experimental Evaluation
LISA-CNN: Built using the LISA dataset (U.S. road signs). Contains three CNN layers and performs with 91% accuracy.

Experimental Evaluation
GTSRB: Based on the German benchmark (GTSRB). U.S. stop signs are used instead of German ones. Achieves 95.7% accuracy on test set, 99.4% on custom stop sign images.

Experimental Evaluation
This slide categorizes the evaluation methods: Stationary tests: fixed camera setup. Drive-by tests: camera on moving car. Poster attacks: full sign perturbation. Sticker attacks: partial, graffiti-style perturbations.

Experimental Evaluation
The table discusses how adversarial stickers are camouflaged as street graffiti to avoid suspicion from human observers, making the attacks stealthier.
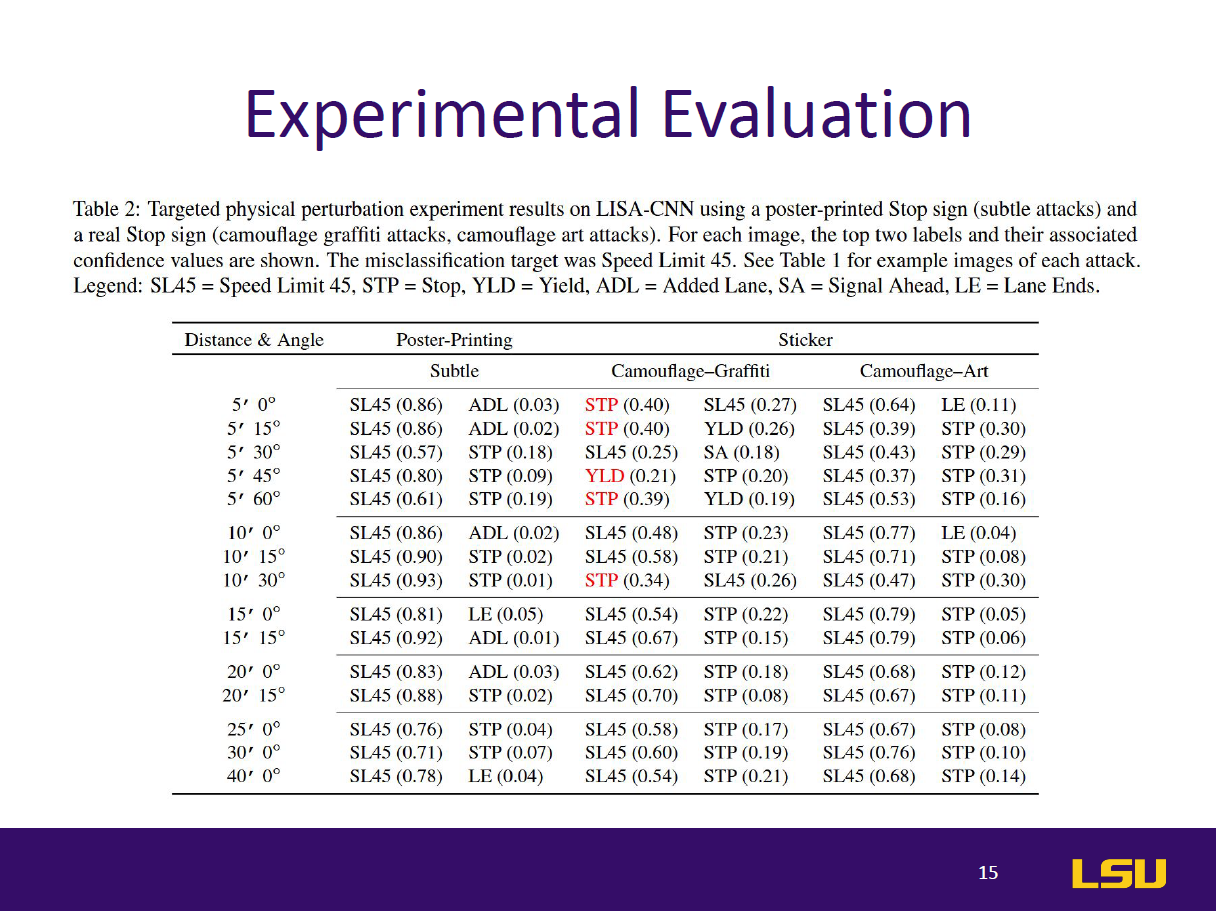
Experimental Evaluation
Results from LISA-CNN is discussed in this section
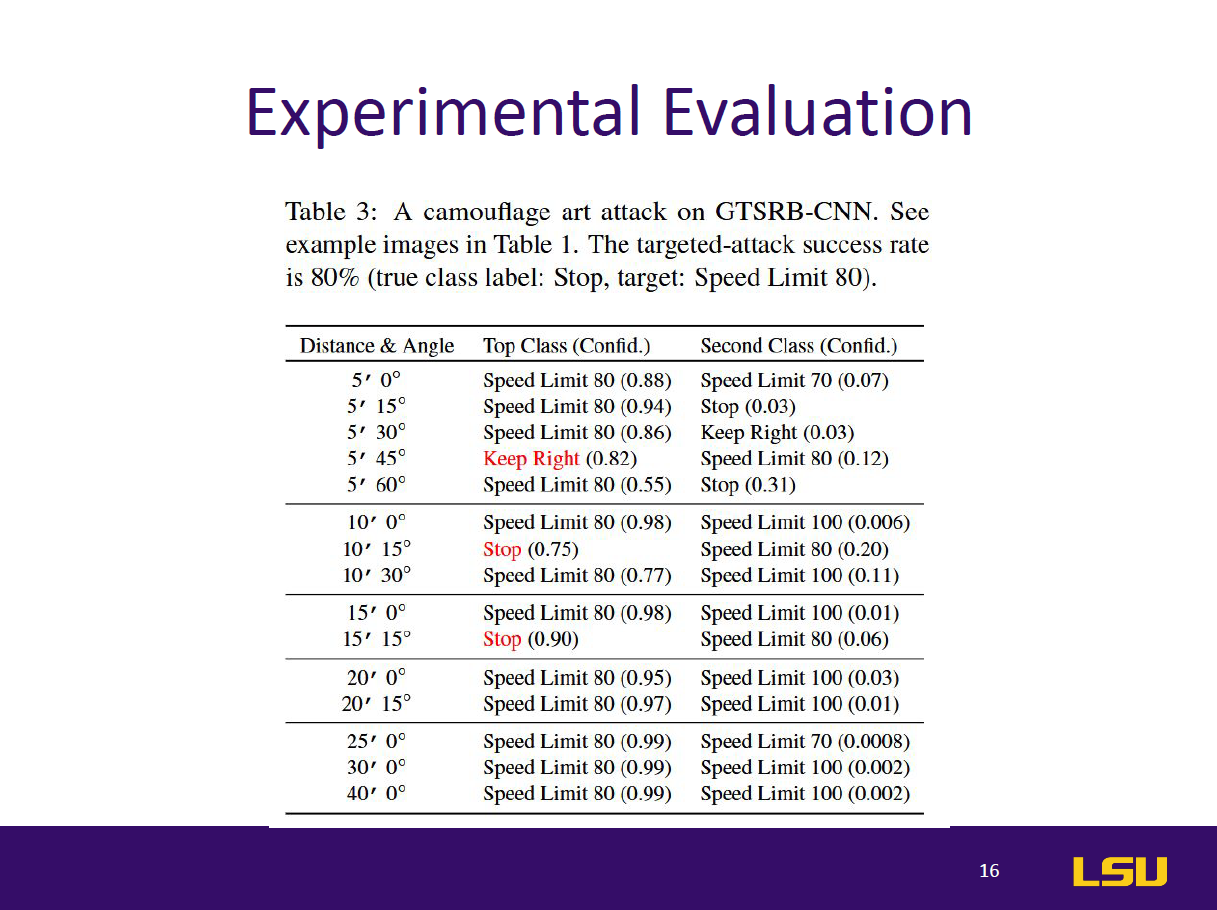
Experimental Evaluation
Results from GTSRB-CNN is discussed in this section

Experimental Evaluation
RP2 is extended to non-road objects: A microwave is misclassified as a phone (90% success). A coffee mug is misclassified as a cash machine (71.4%).

Experimental Evaluation
Cropped images were used to align adversarial examples with original inputs. High success rates were achieved: LISA-CNN: 70% targeted, 90% untargeted. GTSRB-CNN: 60% targeted, 100% untargeted.

Main Insights
This slide emphasizes real-world adversarial attacks are effective and risky. RP2 can generate reliable perturbations across varied conditions. Both lab and real-world (drive-by) tests validate the attack’s effectiveness.

Future Works
Follow-up works: RP2 extended to attack object detectors. Google’s universal adversarial patches. Defense proposals include robustness training and transformation-based defenses.

Presenter thoughts: Strength
The author discusses some strengths such as first to explore real-world attacks for autonomous vehicles. High misclassification success rates. Realistic threat modeling using only altered sign

Presenter thoughts: Weaknesses
The author discusses some shortcomings including assumption white-box access (knowledge of the model). Manual image cropping doesn’t reflect automated systems. Attacks are limited to classifiers, not detectors.
Discussion and Class Insights
Q1: Do you believe the attacks outlined in this work are important to consider as refinement of autonomous vehicle behavior continues?
Q2: What do you believe is the solution to attacks such as sticker attacks on stop signs? Should the AI be trained to identify altered stop signs? Is it possible to train the AI on all types of alterations?
Ruslan Akbarzade: Ruslan emphasized that these types of attacks are important to study because they could impact vehicle behavior. He pointed out that the issue may not lie solely with the model—if the model is robust, it should ideally detect such anomalies. He also noted that even humans might misinterpret altered signs, suggesting that the fault doesn’t rest entirely with the system.
Obiora: Obiora proposed incorporating a cybersecurity agent within the vehicle’s system that can detect and flag potential adversarial attacks early. This agent would alert the system before the altered input misguides the model, acting as a defense mechanism in real-time.
Aleksandar: Aleksandar expressed skepticism about the continued relevance of such attacks, stating that advances in AI have likely made these specific methods outdated. However, he acknowledged the value of understanding past vulnerabilities to strengthen future systems.
Obiora: Obiora added that certain physical attributes—such as the distinct shapes of stop signs versus speed limit signs—could serve as helpful features for classification, even under adversarial attack conditions.
Professor: The professor highlighted the broader significance of the paper for future fully autonomous vehicles. He discussed how targeted attacks, such as those triggered to affect specific users, present serious risks. He praised the experimental design of the paper and stressed the importance of learning how to extract actionable insights from performance metrics and testing methodologies.
Audience Questions and Answers
Professor: What is the distinction between a classifier and a detector in the context of this study?
Answer: With no response, the professor clarified that a classifier identifies what an object is when the object is already isolated (e.g., determining that an image shows a stop sign). In contrast, a detector locates and identifies objects within a broader scene, making it more robust to real-world variability. This difference is significant in understanding the paper’s scope and limitations, as the study focused on classifiers rather than detectors.
Professor: Why did the authors choose the specific architectures (LISA-CNN and GTSRB-CNN) over more modern or complex models?
George: George suggested that the authors may have selected CNN-based classifiers because they were aware of existing vulnerabilities in such architectures. Simpler CNNs are still widely used and serve as a meaningful starting point to demonstrate the feasibility and generalizability of physical adversarial attacks.