DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
Authors: Chenyi Chen, Ari Seff, Alain Kornhauser, Jianxiong Xiao
Presentation by: Ruslan Akbarzade
Time of Presentation: February 11, 2025
Blog post by: Sujan Gyawali
Link to Paper: Read the Paper
Summary of the Paper
The paper "DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving" introduces a novel approach to autonomous driving by predicting key driving affordances rather than processing the entire scene or mapping images directly to commands. Traditional Mediated Perception methods require complex scene reconstruction, while Behavior Reflex methods lack interpretability. The proposed Direct Perception model extracts 13 key affordances such as lane distances, heading angles, and vehicle distances using a Convolutional Neural Network (CNN). This study highlights how Direct Perception improves efficiency, interpretability, and generalization to real-world driving scenarios by balancing perception-based and reflex-based approaches.
Presentation Breakdown
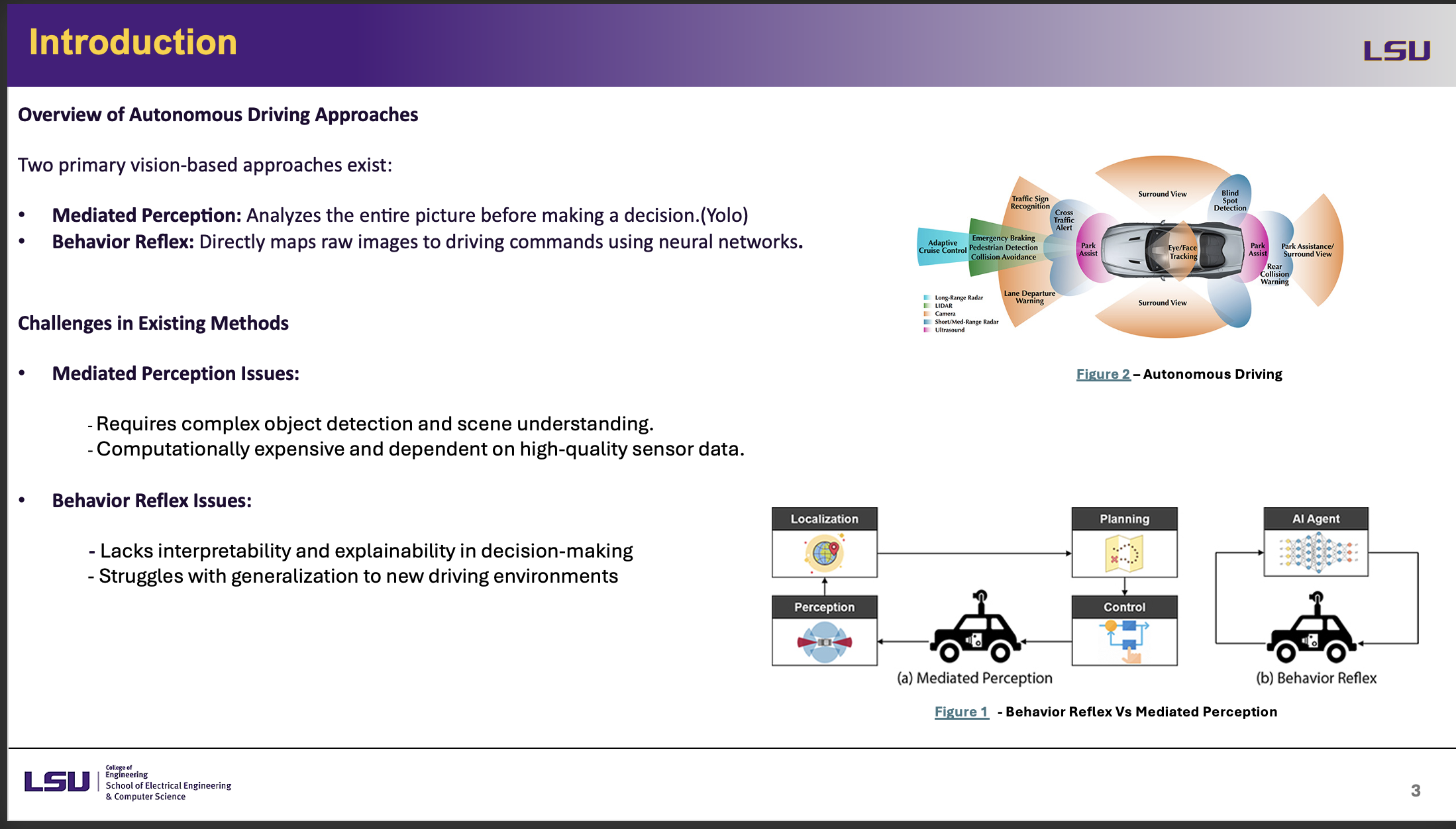
Introduction
The slide introduces the two main vision-based approaches to autonomous driving: Mediated Perception and Behavior Reflex. Mediated Perception uses significant computational resources and sophisticated object detection to examine the whole scene before deciding what to do. Conversely, Behavior Reflex techniques directly translate raw pictures to driving commands, therefore bypassing organized decision-making and speeding but less interpretable and prone to mistakes. The main difficulty is that neither approach is very computationally efficient or practically flexible. The study introduces Direct Perception, a hybrid method that simply extracts the most pertinent driving affordances instead of processing the whole scene, therefore enabling more efficient and interpretable autonomous decision-making to solve these challenges.

Suggested Approach
The slide presents Direct Perception as a middle-ground approach between Mediated Perception and Behavior Reflex. Using a Convolutional Neural Network (CNN), Direct Perception forecasts important driving-related indications (affordances), like lane distances and vehicle closeness, instead of analyzing every object in a scene or directly mapping images to actions. This guarantees disciplined decision-making, lowers computational complexity, and enhances interpretability. Combining the advantages of both conventional approaches, Direct Perception presents a more dependable and effective alternative for autonomous driving.

Key Concepts & Terminology
This slide introduces key concepts in Direct Perception for autonomous driving. Indicators like lane distance and car closeness, driven by affordances, guide decisions without considering the whole scenario. Like the design of a door determines its use, figure 4 shows how affordances shape interactions. For organized decision-making, CNNs layer images and identify edges, lane marks, and road features. Whereas the KITTI dataset guarantees real-world model validation, the TORCS simulator offers a controlled training environment. These components taken together offer an interpretable and more efficient driving model.
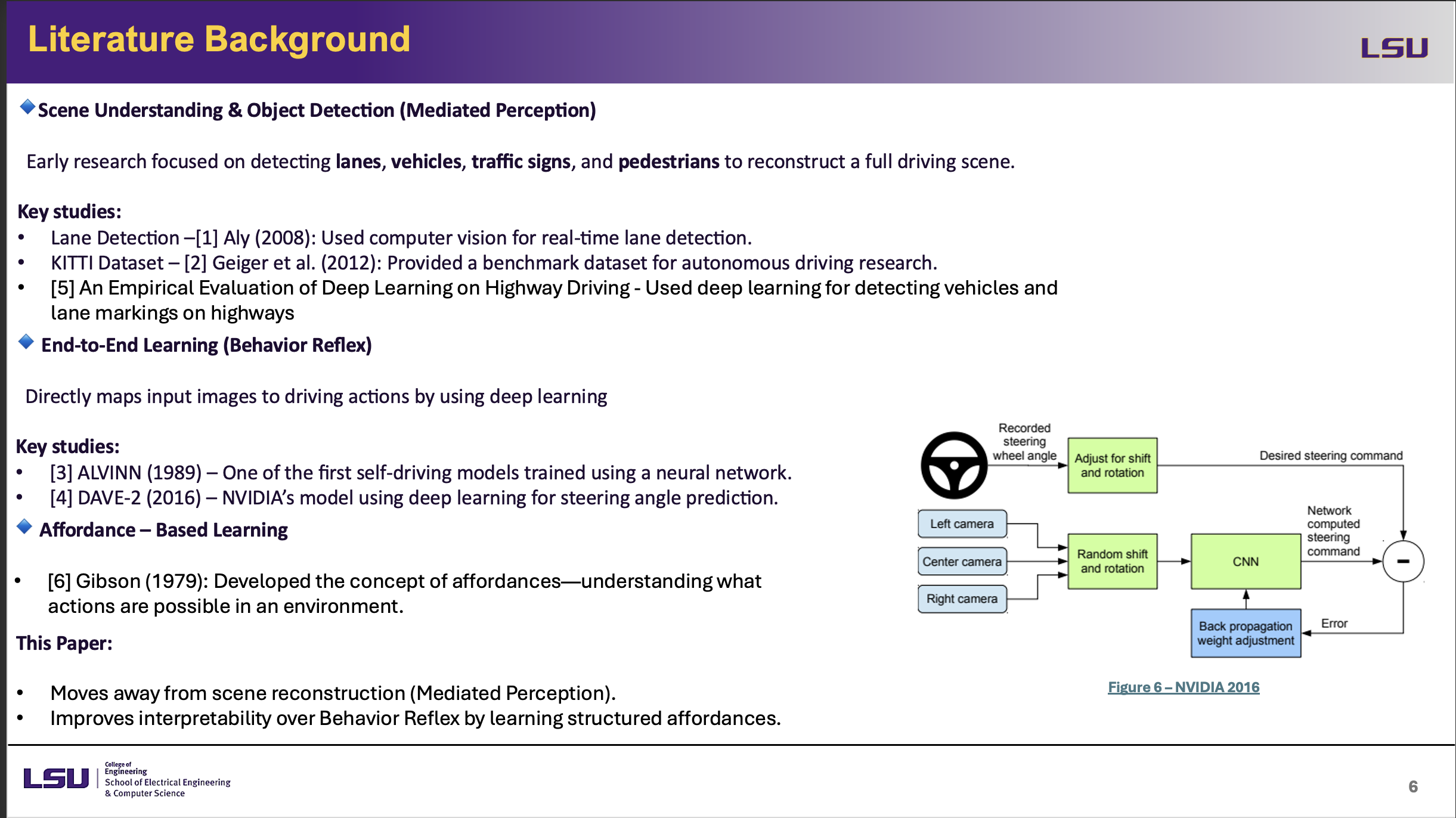
Literature Background
This slide presents an overview of previous research in autonomous driving, focusing on three main approaches. Based on lane detection research (Aly, 2008) and studies like Kitti Dataset (Geiger et al., 2012), Mediated Perception reconstructs a complete driving environment by identifying lanes, vehicles, and traffic signals. Using deep learning, behavior reflex—end-to-end learning—maps raw visuals to driving actions—shown in models such as ALVINN (1989) and NVIDIA's DAVE-2 (2016). Ultimately, Gibson's (1979) Affordance-Based Learning emphasizes on knowing important driving signs instead of whole scene reconstruction.

Contributions of the Paper
This slide presents the key contributions of the paper, introducing Direct Perception as a new paradigm that predicts key driving indicators (affordances) instead of analyzing every object in a scene.CNNs are used in the method to estimate 13 affordances including heading angle, vehicle proximity, and lane distances. The results show that by avoiding complicated object identification and substituting structured driving signs instead of raw commands, Direct Perception is more efficient than Mediated Perception and surpasses Behavior Reflex. It offers a small and significant picture of the driving scene, therefore bridging perception and control. Furthermore proving successful sim-to-real transfer and real-world generalization is the method.

Data Collection
This slide presents the data collection methodology used to train the model, focusing on pre-defining 13 driving affordances and leveraging a convolutional neural network (CNN) to detect them for generating driving indicators. TORCS, a freely available open-source driving simulator, was used for dataset collecting. For twelve hours on the simulator, a human driver manually drove a car to generate a dataset of driving images matched with associated affordances. To increase model generality, the gathered data comprised several road designs, lane layouts, and traffic circumstances. Three main kinds of data were gathered: speed and spatial data for tracking the driving environment; RGB images of the road ahead as input for the CNN; affordance indicators such lane distances, vehicle closeness, and heading angle. This ordered dataset improves the model's flexibility in real-world driving conditions and helps it to effectively learn important driving signs.
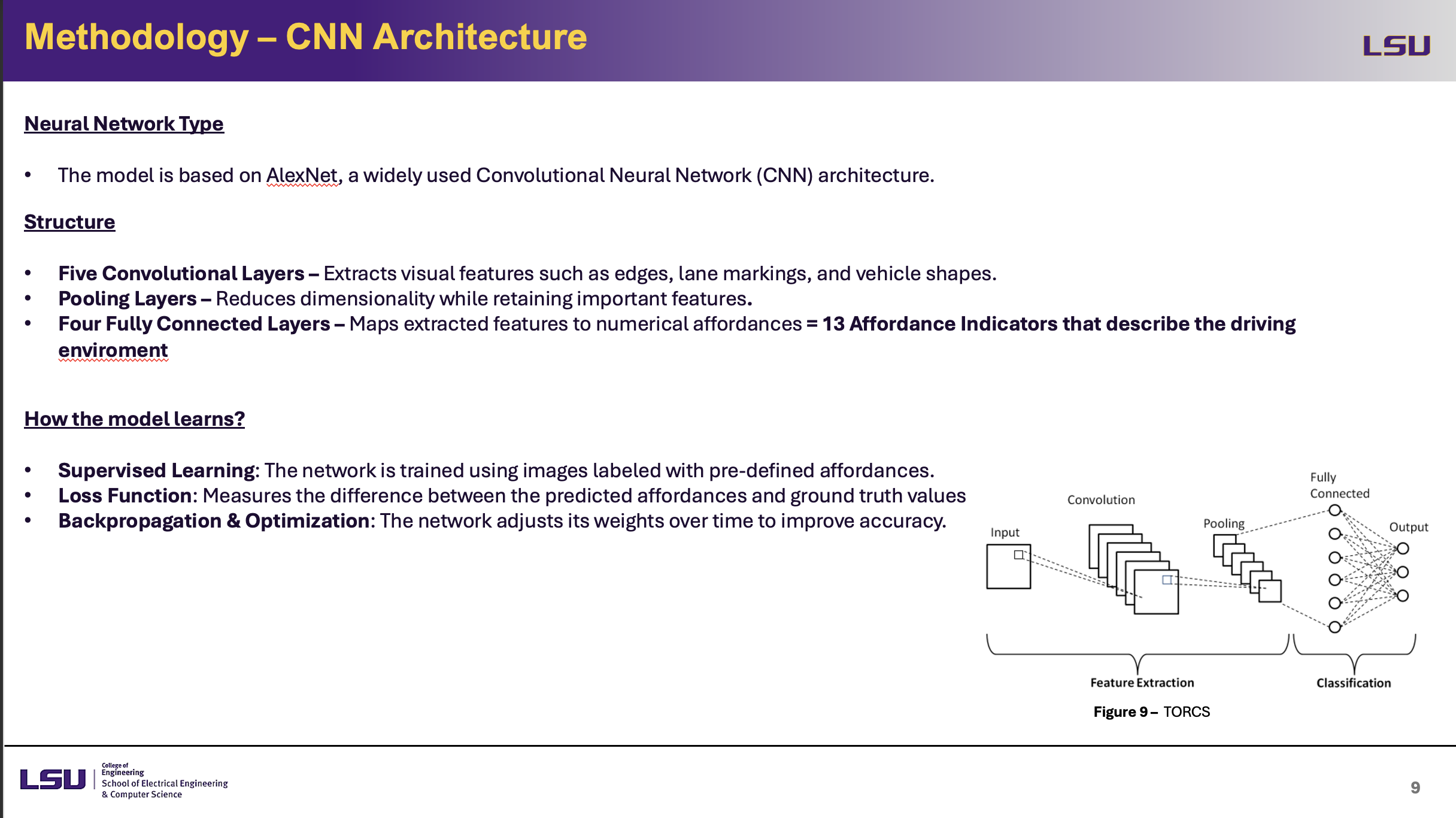
CNN Architecture
This slide presents the CNN architecture used in the model, which is based on AlexNet, a widely used convolutional neural network (CNN). Following pooling layers that lower dimensionality while maintaining important details, the network comprises five convolutional layers extracting fundamental visual information including edges, lane markers, and vehicle shapes. These retrieved features are mapped to 13 affordance markers by the last four completely connected layers, therefore offering a structured depiction of the driving environment. The model learns using supervised learning that is, on images tagged with preset affordances. Whereas backpropagation and optimization change the network's weights over time to improve accuracy, a loss function gauges the gap between anticipated and actual values. Effective decision-making guaranteed by this architecture guarantees dependability and interpretability of autonomous driving models.
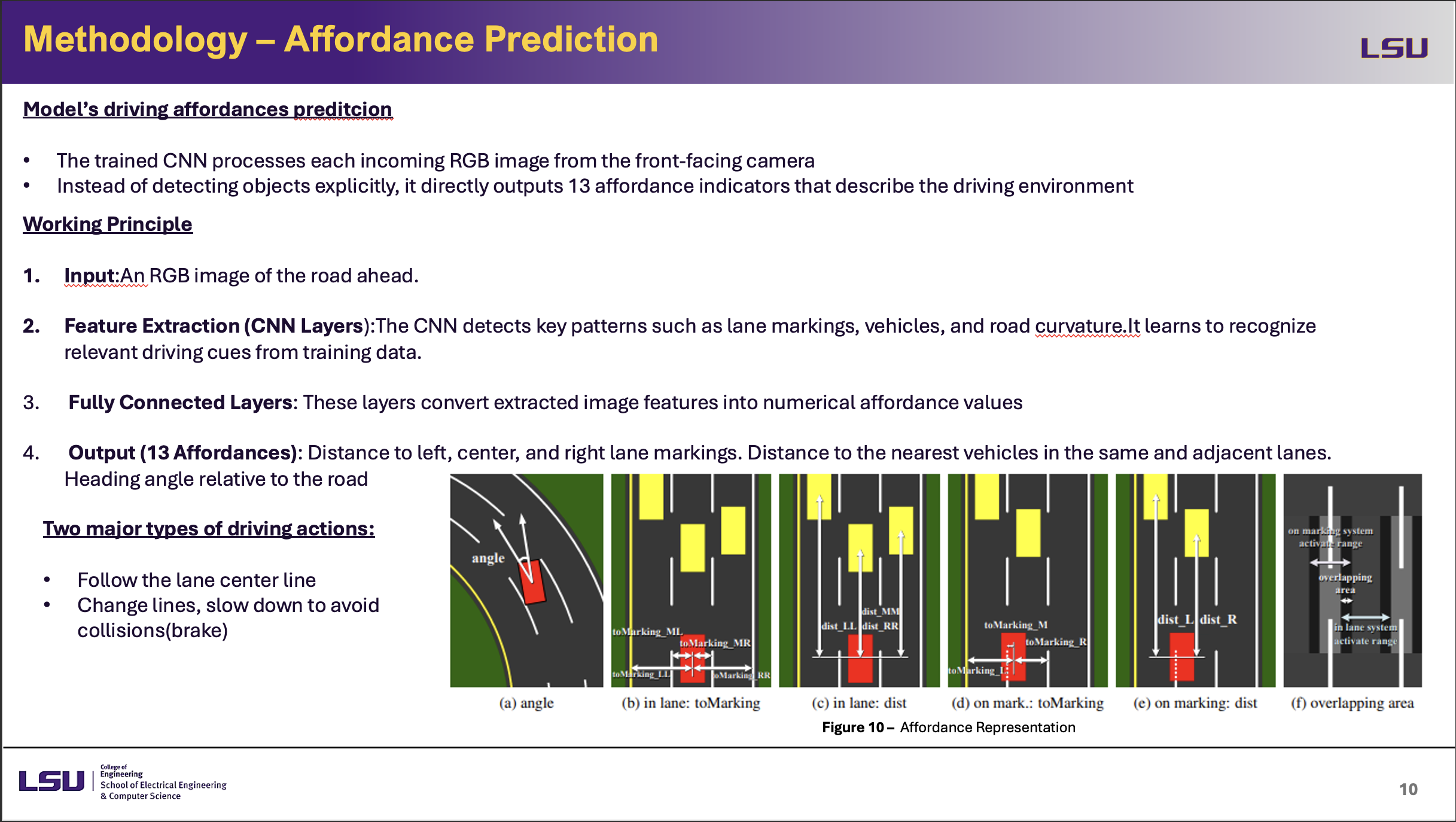
Affordance Prediction
This slide presents the affordance prediction approach used in the model.For every incoming RGB image from the front-facing camera, the trained CNN directly predicts 13 affordance markers that characterize the driving environment rather than identifying specific objects. Starting with the input image, CNN layers that identify lane markings, cars, and road curvature feature extraction, so transforming the image. Full connected layers transform the retrieved features—including lane distances, vehicle distances, and heading angle relative to the road—into numerical affordance values. Two main driving actions are made possible by the model: following the lane center line and switching lanes or slowing down to prevent runs-on. Figure 10 graphically shows how many affordances help to make decisions, hence enhancing efficiency and interpretability in autonomous driving.

Affordance to Action Mapping
This slide presents how affordances are mapped to driving actions in autonomous systems. Though they are not direct orders for steering or throttle, the CNN generates 13 affordances. Rather, a controller uses these affordances to ascertain suitable driving behavior. Three main components define the decision-making process: Steering Control, whereby the system modifies the steering angle depending on lane markings and heading angle; Speed Control, whereby the model slows down if a vehicle is detected ahead, otherwise maintaining a constant speed (~72km/h in simulations); and Lane Change Decision, whereby the system checks lane availability and space before switching lanes. Should both lanes be crowded, the model slows down and waits for a gap. Figure 11 shows the controller logic and how dynamically in real-time affordances influence actions.
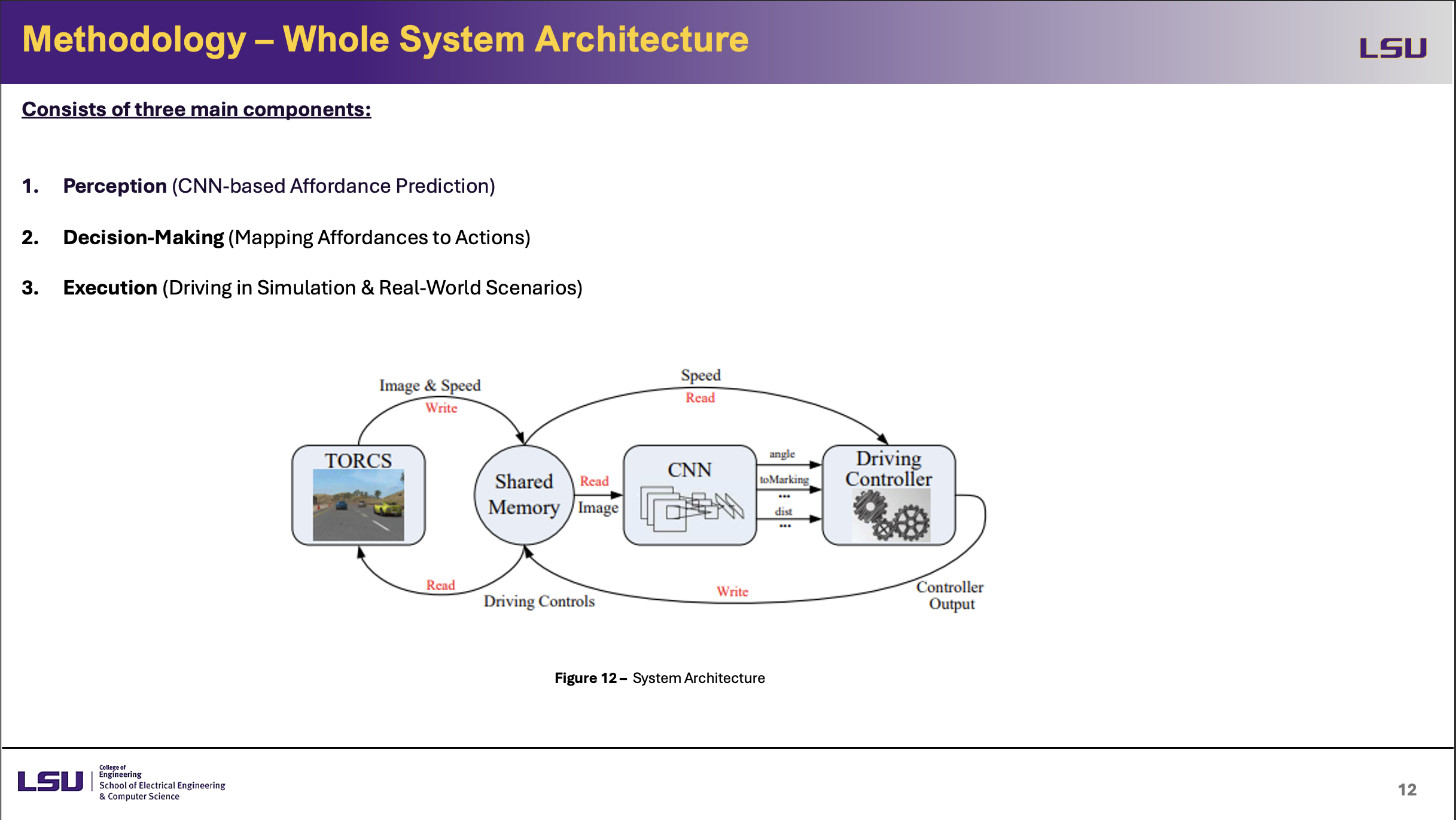
Whole System Architecture
This slide presents the overall system architecture for autonomous driving, which consists of three main components: Perception, Decision-Making, and Execution.Perception consists on CNN-based affordance prediction, in which the model derives important driving signals from visuals. Decision-making translates these affordances to certain driving actions with a controller. At last, execution is carrying out these steps in real-world and simulated environments. Data is gathered from the TORCS simulator, passed through a shared memory module, evaluated by the CNN for affordance prediction, and lastly the driving controller decides the vehicle's actions depending on the computed affordances in Figure 12.
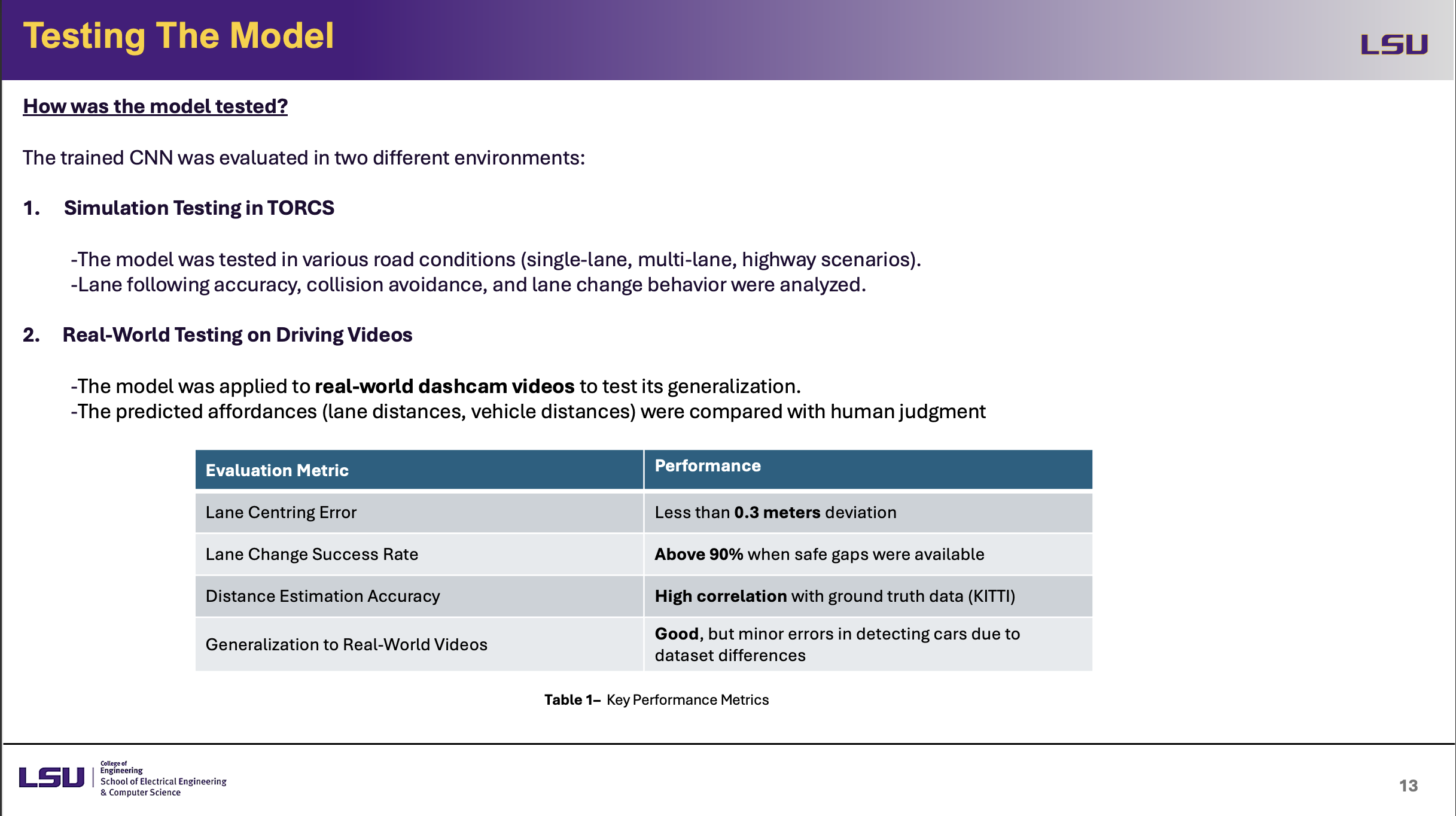
Testing The Model
This slide presents how the trained CNN model was evaluated in two different environments: simulation testing in TORCS and real-world testing using driving videos. The model was tested in simulation under several road situations including single-lane, multi-lane, and highway scenarios to evaluate lane-following accuracy, collision avoidance, and lane-changing behavior. The model was tested practically using dashcam videos to assess its capacity to extend beyond simulation. Human judgment was matched with the expected affordances—that which included lane distances and vehicle proximity. Key performance measures are compiled in Table 1 from which a lane-centering error of less than 0.3 meters, a lane change success rate of 90%, and strong correlation with ground truth data from KITTI demonstrate. The model did well, although due to dataset variations slight car detection errors were noted.
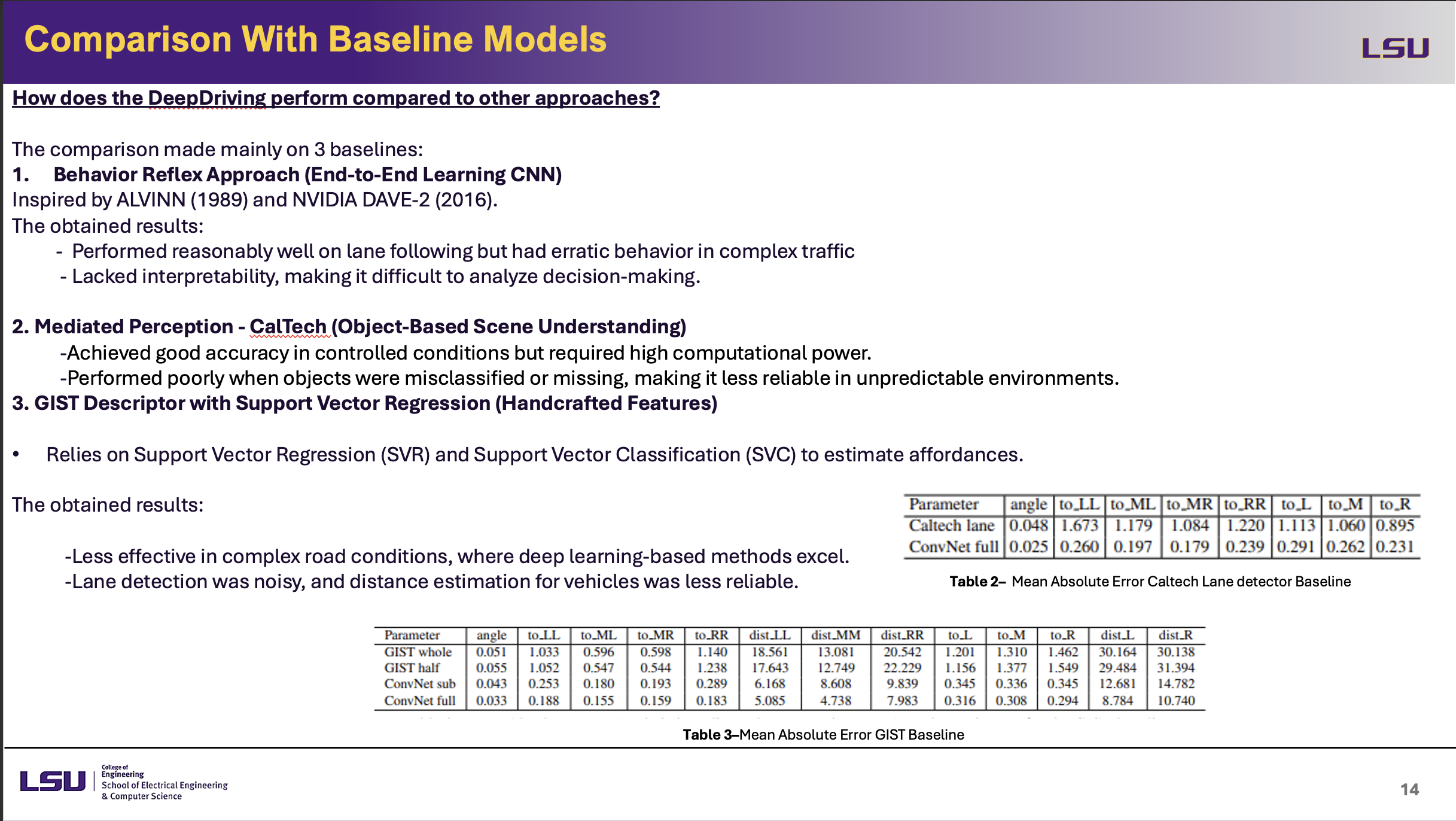
Comparison With Baseline Models
This slide compares DeepDriving with three baseline models: Behavior Reflex Approach, Mediated Perception, and GIST Descriptor with Support Vector Regression. While showing erratic behavior in complex traffic, the Behavior Reflex Approach did well in lane following. Mediated Perception struggled with high processing costs and object misclassification while nevertheless obtaining accuracy in controlled environments. Dependent on handcrafted characteristics, GAST Descriptor with SVR was less effective in complex settings, which resulted in noisy lane detection and inaccurate distance estimate. The tables indicate DeepDriving's better performance by a quantitative comparison.

Strengths & Limitations
Predicting only important affordances allows the Direct Perception Approach to provide effective decision-making by avoiding the complexity of complete scene awareness. Since it offers organized driving indicators rather than raw steering orders, it is more understandable than end-to- end education. On real-world data, the model performs satisfactorily on dashcam films. Furthermore computationally efficient since it reduces computing resources by removing the need for complete object recognition. Limitations exist, though- The model depends on pre-defined 13 affordances, therefore limiting adaptability. Real-world differences could lead to failures; lane change decisions follow rule-based logic, hence dense traffic navigation is difficult.

Future Improvements/Suggestions
The slide presents potential improvements for enhancing the model's performance. Using more varied training data can assist the model to generalize better to real-world driving scenarios. The slide advises using advanced decision-making or reinforcement learning to handle lane change difficulties in heavy traffic by smoothing out transitions. At last, the slide offers a forum for any other recommendations to improve the strategy.

Review and Thoughts
The slide presents a review of the paper, highlighting its main contributions, strengths, weaknesses, and potential improvements. The major contribution is in presenting Direct Perception as an interpretable substitute for end-to-end driving. It proves successful sim-to-real transfer in real-world settings and shows that a CNN can forecast significant affordances without explicit object detection. Among the positives include computing efficiency, improved interpretability over Behavior Reflex, and applicability to both simulated and real-world settings. Weaknesses in specified affordances, a lack of high-level scene knowledge, and simple lane-changing logic abound, nevertheless. The slide offers suggestions for improvement include adding adaptable affordances, mixing affordance-based models with object-based perception, and using reinforcement learning to support better lane-changing judgments.

Lesson and Takeaways
The slide presents key takeaways from the paper, emphasizing that affordance-based learning serves as a middle ground between full scene understanding and end-to-end learning. It highlights that training in simulation is effective, but adapting models to real-world environments remains a challenge. The field is shifting towards data-driven and reinforcement-based approaches rather than solely relying on predefined affordances. Lastly, the slide underlines that explainability is a crucial challenge in AI-driven systems, as interpretability plays a significant role in self-driving decisions.

Open Questions and Discussions
The slide presents key discussion points about the future of self-driving technology. It questions whether simulation alone is enough to fully train self-driving cars, considering missing real-world factors like weather, road conditions, and human unpredictability. Another point explores the idea of defining more than 13 affordances, asking if including pedestrian locations or driver intent could improve the system’s decision-making. Finally, it raises an interesting debate: Would AI-driven cars improve traffic flow if human drivers were removed? These open questions invite further exploration and discussion.
Discussion and Class Insights
Q1: Can we fully train self-driving cars in Simulation? Do you know any other simulation enviroments?
George: George says he has observed AI was initially trained using games like chess and Go, later evolving to more complex environments. He wonders if a similar approach could apply to self-driving by using real-world Dashcam footage to analyze crash scenarios and develop AI behaviors to avoid them. George suggests that simulation is especially useful for training AI in rare but critical situations, such as crash avoidance. By continuously gathering data from autonomous vehicles and feeding it into simulations, AI could improve decision-making. However, real-world data remains essential, as simulations alone may not capture all unpredictable scenarios. In summary, George believes that while simulations are valuable for refining AI, a hybrid approach combining both simulation and real-world data is necessary for training reliable self-driving cars.
Bassel: Bassel says that while simulation is useful, there might be unexpected scenarios in real driving that simulations can't fully capture. He gives an example of a Tesla accident in Saudi Arabia, where a car crashed into a camel, highlighting how self-driving models may struggle with rare and unpredictable obstacles. This shows the need for real-world testing to improve AI decision-making in diverse environments.
Q2: In this paper, 13 affordances used. What if we define more affordances?
Bassel: Bassel says that the researchers may have already identified the most important affordances, so increasing the number of affordances does not necessarily improve performance. Adding more affordances could increase complexity without significant benefits, and it may lead to unnecessary computational overhead. Instead, focusing on optimizing the existing affordances might be a more effective approach.
Q3: If all cars on the road were Al-driven, would traffic flow better with purely machine-optimized decision-making?
Bassel: Bassel says that if all cars were AI-driven, traffic flow could improve due to optimized decision-making and reduced human errors. However, he also notes that challenges like unpredictable situations, system failures, and ethical concerns must be addressed. He suggests that while AI can enhance efficiency, a fully AI-driven system would require advanced infrastructure and thorough testing to ensure safety.
Audience Questions and Answers
Professor: Could you explain behavioral reflex models? How do they work compared to mediative perception?
Ruslan: Yes, there are key differences between the two. Mediative perception involves perception, localization, planning, and control, meaning it analyzes the entire scene before making a decision. In contrast, behavioral reflex models rely on a single AI agent making decisions. These models are trained by recording human driving behavior for extended periods, such as 12 hours, to learn reflexive responses. For example, if a car stops, the model learns how a human would typically react in that situation.
Professor: What type of input data does the behavioral reflex model use?
Ruslan: The model primarily uses sensor data rather than images. However, raw images are still part of the input, as the model processes visual information alongside sensor readings.
Professor: How does the enabling model record human behavior? How does it work in the learning process?
Ruslan: It’s a combination of both raw images and sensor data. The system records how the car behaves in response to different driving scenarios, capturing patterns in human decision-making. This data is then used to train the AI model, allowing it to mimic human reflexes in similar situations.
Obiora: Have there been real-world implementations of this method in popular self-driving car companies? What test candidates are used for perception and decision-making?
Ruslan: I haven’t encountered real-world examples of this specific method being implemented in commercial self-driving cars. Most of the research is still in the theoretical stage, primarily explored through academic papers. However, there may be more recent studies building on these concepts.
Obiora: Have these methods been applied to self-parking or other driving conditions?
Ruslan: Self-parking is a bit simpler compared to this approach. This method focuses more on decision-making in dynamic driving conditions, such as slowing down when there’s a car ahead, overtaking vehicles, and lane changes. While self-parking systems rely on sensors and predefined movements, this method aims to optimize real-time driving decisions.

References
[1] M. Aly, (2008). Real-time lane detection.
[2] Geiger et al., (2012). KITTI Dataset.
[3] D. A. Pomerleau, (1989). ALVINN.
[4] NVIDIA DAVID-2, (2016).
[5] Huval et al., (2015). Deep Learning on Highway Driving.
[6] J. J. Gibson, (1979). The ecological approach to visual perception.